
Benvenuto nella rubrica Tech Explained!
Come ormai si sente ripetere alla nausea, in ambito di Intelligenza Artificiale e nella Data Science in generale i dati costituiscono il cuore di qualsiasi progetto. La gestione dei grandi, spesso immensi, volumi di dati impiegati per la produzione dei modelli predittivi più disparati non è mai un compito banale e si avvale sempre di uno strumento fondamentale: il database. In generale, un database può essere considerato come un luogo sicuro dove archiviare grandi quantità di dati in modo ordinato. Si pensi ad un’enorme biblioteca protetta da un sistema di sicurezza impenetrabile (o quasi).

Di seguito sono riportate alcune delle ragioni principali per le quali l’utilizzo dei database risulta imprescindibile. Dunque:
- Organizzazione dei dati: i database permettono di strutturare l’archiviazione dei dati in modo ordinato, rendendoli facilmente accessibili e manipolabili.
- Efficienza nella gestione dei dati: quando si tratta di dataset di grandi dimensioni (dicesi “dataset” un generico insieme di dati), l’efficienza diventa fondamentale. I database ottimizzano il processo di recupero e manipolazione dei dati, riducendo significativamente il tempo necessario per effettuare operazioni complesse su di essi (come ad esempio estrazioni di specifici sottoinsiemi di dati o la fusione di diversi dataset).
- Sicurezza e controllo dell’accesso: i database offrono funzionalità avanzate per la gestione della sicurezza, permettendo di controllare chi può accedere ai dati e quali operazioni possono essere eseguite su di essi.
- Scalabilità: i database sono progettati per gestire l’aumento esponenziale della quantità di dati da archiviare. Questa caratteristica è particolarmente importante nell’ambito di progetti di intelligenza artificiale, dove la quantità di dati può crescere rapidamente in seguito all’aggiunta di nuove fonti o semplicemente con l’espansione del progetto.
I database sono quindi strumenti essenziali per gestire in modo efficiente e sicuro le grandi quantità di dati che, in un progetto di sviluppo di intelligenza artificiale, possono spaziare da semplici tabelle con migliaia o milioni di righe a complessi archivi contenenti dati eterogenei (come ad esempio foto, video e file audio).
In materia di database è prima di tutto importante distinguere tra “database relazionali” e “database non relazionali”. Dunque:
Database relazionali: i database relazionali sfruttano uno schema predefinito tramite il quale i dati sono organizzati in tabelle composte da righe e colonne. Sulle righe si hanno le diverse osservazioni del dataset, mentre sulle colonne si hanno le variabili che descrivono ciascuna osservazione. Ogni tabella ha una struttura accuratamente predefinita, secondo la quale ciascuna colonna può contenere solamente un tipo di dato specifico (ad esempio, la stessa colonna non può contenere in due righe diverse un valore numerico e uno testuale). Le tabelle sono interconnesse tramite relazioni (da qui il nome “database relazionale”) basate sulle cosiddette “chiavi primarie” (in inglese, “primary keys”) e “chiavi esterne” (in inglese, “foreign keys”), le quali permettono di collegare i dati presenti in tabelle distinte in modo strutturato e coerente (non si approfondiranno, in questa sede, i concetti di chiavi primarie ed esterne). Le operazioni effettuabili sui dati contenuti nelle tabelle di un database relazionale sono eseguite tramite il linguaggio SQL (Structured Query Language) il quale, nonostante presenti molte varianti generalmente dovute alla diversa azienda fornitrice del servizio (ovvero del database), costituisce sostanzialmente uno standard a livello mondiale. In gergo, tutte le operazioni effettuabili su un database relazionale tramite il linguaggio SQL prendono il nome di “query” (traducibile in italiano come “interrogazione”, “domanda”). Di seguito è riportato un esempio di query per l’estrazione di un determinato insieme di dati. Si ipotizzi che un supermercato disponga di un database contenente tutte le singole transazioni di acquisto effettuate da ogni cliente. La tabella “transazioni”, tra le varie colonne, contiene la colonna “id_cliente”, riportante un numero identificativo univoco relativo a ciascun cliente, la colonna “valore_acquisto”, contenente l’ammontare totale del valore della merce acquistata dal cliente in una specifica transazione e la colonna “data_acquisto”, nella quale è presente la data in corrispondenza della quale è avvenuta la transazione d’acquisto da parte del cliente. Segue la query. Dunque:

La query riportata estrae dal database tutte le righe appartenenti alla tabella “transazioni”, limitatamente alle colonne “id_cliente”, “valore_acquisto” e “data_acquisto”, includendo solamente i casi nei quali la data contenuta nella colonna “data_acquisto” sia compresa tra il 2023-01-01 ed il 2023-06-30. In altre parole, tramite questa query si estraggono dalla tabella solamente gli identificativi dei clienti, l’ammontare totale del valore della merce acquistata e la data in corrispondenza della quale è avvenuto l’acquisto relativi alle transazioni avvenute tra il primo gennaio ed il trenta giugno 2023. In rosso sono evidenziate le parole chiave del linguaggio SQL presenti in questa specifica query.
Di seguito è riportata la tabella “transazioni” prima e dopo la query eseguita su di essa. Dunque:
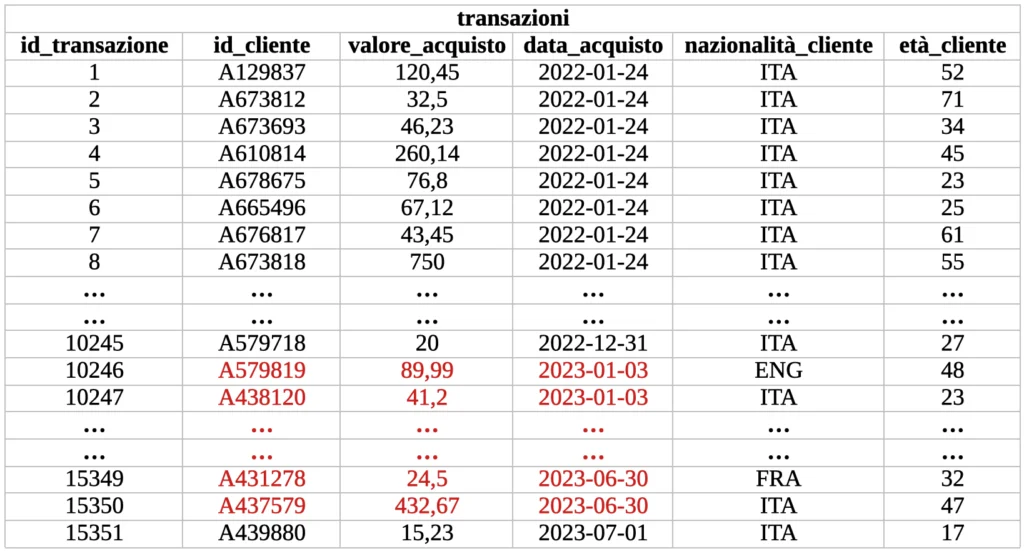
I dati evidenziati in rosso sono quelli selezionati dalla query riportata nell’esempio, la quale produrrà il seguente sottoinsieme dell’insieme “transazioni”. Dunque:
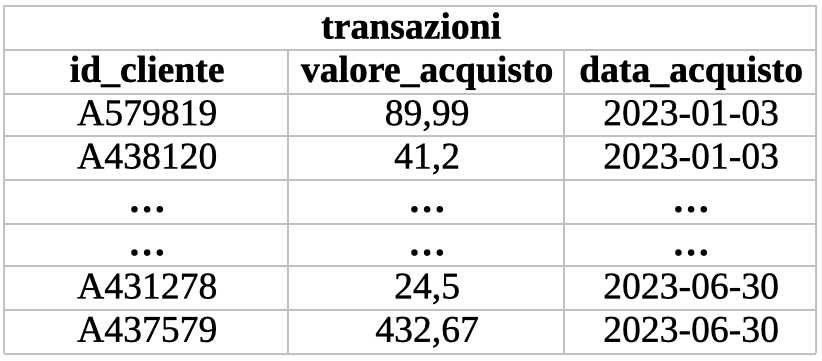
Oltre all’indubbio valore risiedente nella standardizzazione del linguaggio per l’interazione con i database relazionali, il principale vantaggio nell’adozione del modello relazionale consiste nella garanzia di coerenza ed affidabilità dell’archiviazione dovuta alla struttura rigida ed ai vincoli di integrità tra le diverse tabelle garantiti dalla presenza delle chiavi primarie ed esterne. I database relazionali sono quindi ideali per applicazioni in cui la coerenza dei dati, l’affidabilità delle operazioni e l’integrità delle relazioni sono fondamentali. Esempi di applicazioni di questo genere includono sistemi di gestione di dati bancari e finanziari, sistemi di gestione delle risorse umane, sistemi di gestione delle interazioni tra azienda e cliente (i cosiddetti “Customer Relationship Management” – CRM).
Database non relazionali: anche detti comunemente database “NoSQL”, i database non relazionali sono caratterizzati da una grande flessibilità nell’archiviazione dei dati dovuta all’assenza degli schemi fissi e rigidi tipici dei database relazionali. In assenza di tale rigidità, l’archiviazione dei dati è libera di assumere le forme più svariate; si hanno quindi i modelli “a grafo”, “a documenti”, i modelli “chiave – valore”, i cosiddetti schemi “a famiglia di colonne”. Di seguito si approfondisce brevemente il database NoSQL con struttura “a grafo”. Si consideri il seguente esempio. Dunque:
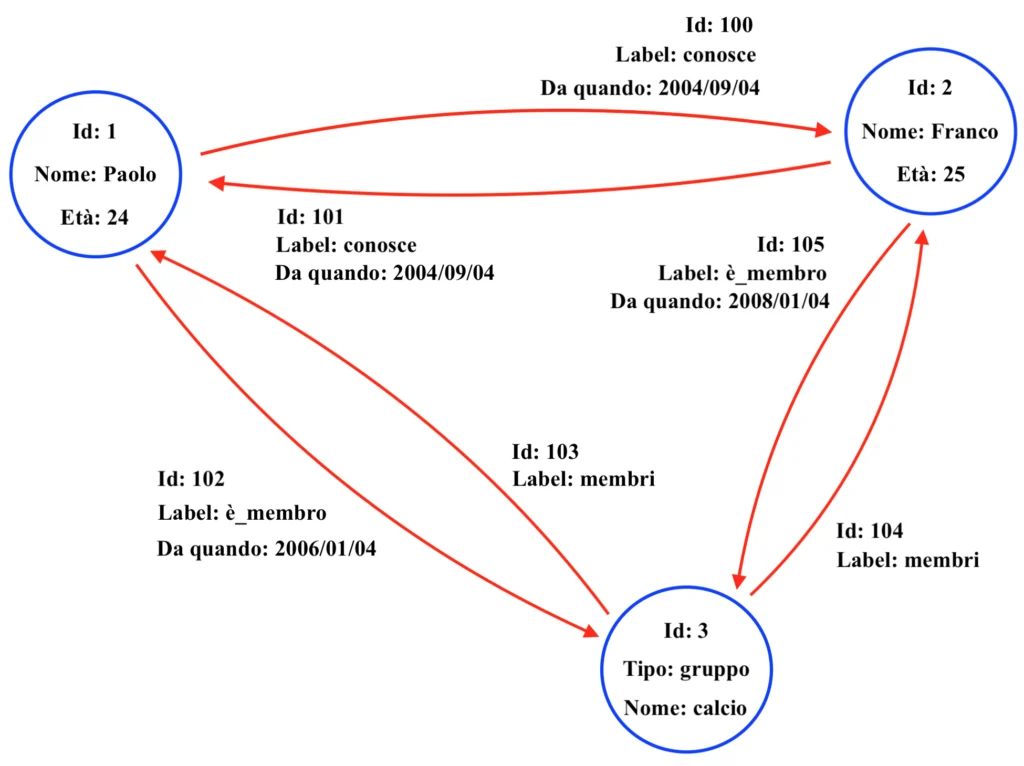
A differenza dei database relazionali, i quali organizzano i dati in tabelle con righe e colonne, un database a grafo utilizza nodi, archi, proprietà ed etichette per modellare e memorizzare le informazioni. L’adozione di questo tipo di database risulta particolarmente efficiente nella gestione di dati caratterizzati da relazioni complesse, come ad esempio quelli derivanti dalle reti sociali. Gli elementi fondamentali di un database con struttura a grafo sono i seguenti. Dunque:
- Nodi: i nodi del grafo rappresentano le entità o gli oggetti appartenenti al sistema in questione. Ogni nodo può avere proprietà che descrivono l’entità che rappresenta. Nell’esempio, il nodo con codice identificativo 1 rappresenta una persona di 24 anni di nome Paolo, il nodo con codice identificativo 2 una persona di 25 anni di nome Franco, il nodo con codice identificativo 3 un gruppo di persone di nome “calcio” (ossia, verosimilmente, una squadra di calcio).
- Archi: gli archi del grafo rappresentano le relazioni sussistenti tra i nodi. Ogni arco collega due nodi e può essere orientato o non orientato. Come i nodi, anche gli archi possono avere proprietà che descrivono in modo maggiormente dettagliato la relazione. Nell’esempio, l’arco con codice identificativo 100 indica che esiste una relazione di conoscenza tra Paolo e Franco, la quale è iniziata, dal punto di vista di Paolo, in data 2004/09/04 (e, infatti, la stessa data è riportata sulla relazione 101 che definisce il rapporto di amicizia tra Paolo e Franco dal punto di vista di Franco).
- Proprietà: le proprietà sono informazioni aggiuntive associate a nodi ed archi e possono includere attributi come “Nome”, “Data”, “Peso” o qualsiasi altro dettaglio rilevante per meglio definire il nodo o la relazione in questione. Nell’esempio, la proprietà “Nome” definisce nei nodi 1 e 2 il nome della persona e nel nodo 3 il nome assegnato al gruppo di persone. Le proprietà aiutano dunque a descrivere in modo maggiormente dettagliato entità e relazioni del grafo.
- Etichette: in inglese anche dette “Labels”, le etichette fanno capo a specifiche categorie che possono essere assegnate ai nodi o agli archi per classificare ed organizzare i dati. Ad esempio, un nodo potrebbe riportare un’etichetta con la categoria “Persona” o “Azienda”, mentre un arco potrebbe esporre l’etichetta riportante “Lavora per” o “Amico di”. Nell’esempio sopra, le etichette apposte alle relazioni tra Paolo e Franco riportano la scritta “conosce”, specificando che si tratta di una relazione di conoscenza. L’approccio a grafo è particolarmente potente per individuare relazioni indirette tra i vari nodi; un esempio di query (ovviamente, la query dovrà essere tradotta in un codice specifico per l’interazione con un database a grafo) può essere il seguente:
“trova tutte le persone che sono amici di amici di una persona specifica”
Sorvolando sulle peculiarità di ciascuna diversa tipologia di database NoSQL, la caratteristica principale che accomuna tali database è la grande flessibilità nell’archiviazione dei dati i quali, in questi casi, possono essere particolarmente complessi e in formati impossibili da gestire per un database relazionale (un esempio sono i dati sotto forma di immagini o video, i quali non possono in alcun modo essere inseriti all’interno di una tabella di un database relazionale). Il prezzo di tale flessibilità tuttavia è l’assenza di un linguaggio standardizzato come SQL per l’interrogazione del database e la gestione dell’archiviazione dei dati al suo interno, caratteristica, questa, che mina fortemente l’interoperabilità tra soluzioni di archiviazione che adottano approcci NoSQL diversi e tra soluzioni NoSQL e database relazionali (basti pensare quanto può essere complesso migrare o mettere in relazione dati provenienti da una struttura “a grafo” con dati organizzati secondo una struttura relazionale). I database non relazionali sono quindi adatti per applicazioni che richiedono flessibilità dei dati e gestione di grandi volumi di dati non strutturati o semi-strutturati. Tipici esempi sono le applicazioni social media ed e-commerce.
Francesco