
Benvenuto nella rubrica How It Works!
Le reti neurali artificiali (in inglese, “Artificial Neural Network” – ANN) sono senz’altro tra le soluzioni di machine learning più celebri ed utilizzate. Di seguito ne approfondiremo il funzionamento, senza scendere eccessivamente negli aspetti tecnici più complessi.
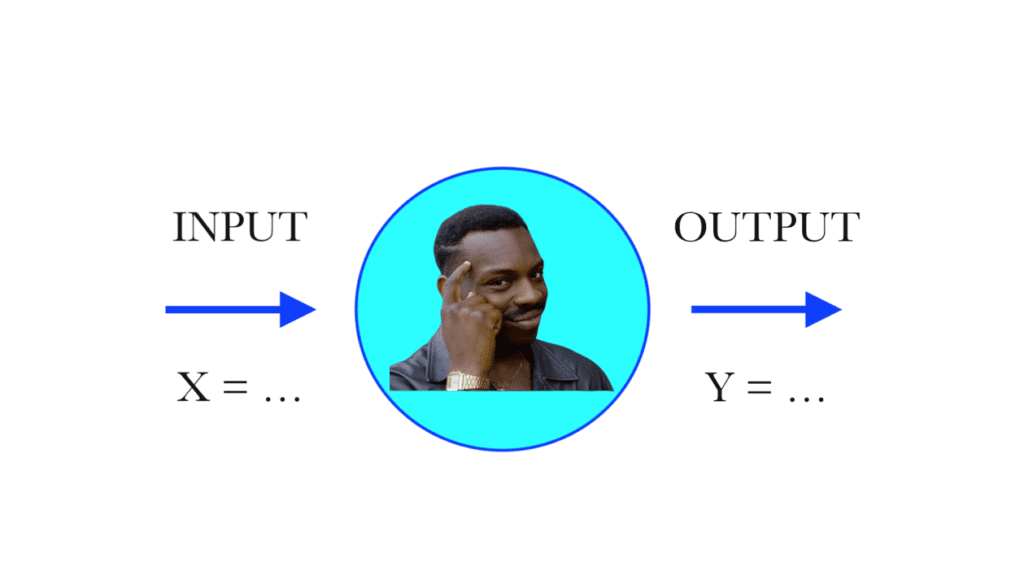
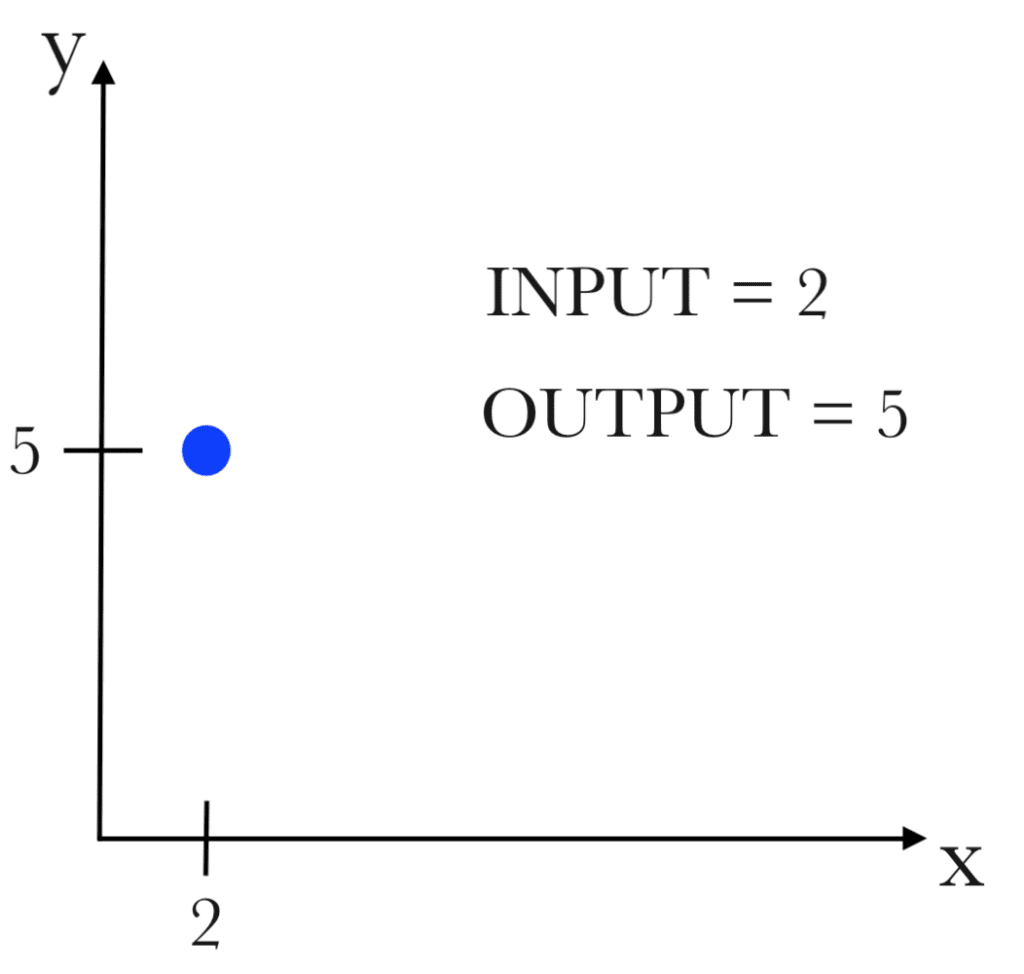
L’unità fondamentale di una rete neurale artificiale è il neurone artificiale, il quale non è altro che una funzione matematica che riceve un input numerico e ne restituisce un altro. Si può semplicemente pensare ad un neurone artificiale come ad un diagramma cartesiano nel quale, ad un valore della variabile x, ovvero ad un input, viene associata secondo una specifica regola un valore della variabile y, ovvero un output.
I neuroni artificiali sono organizzati in strati consecutivi i quali, secondo l’architettura di rete più semplice, sono “densamente connessi” gli uni agli altri; ciascun neurone di uno strato è collegato a tutti quelli dello strato successivo.
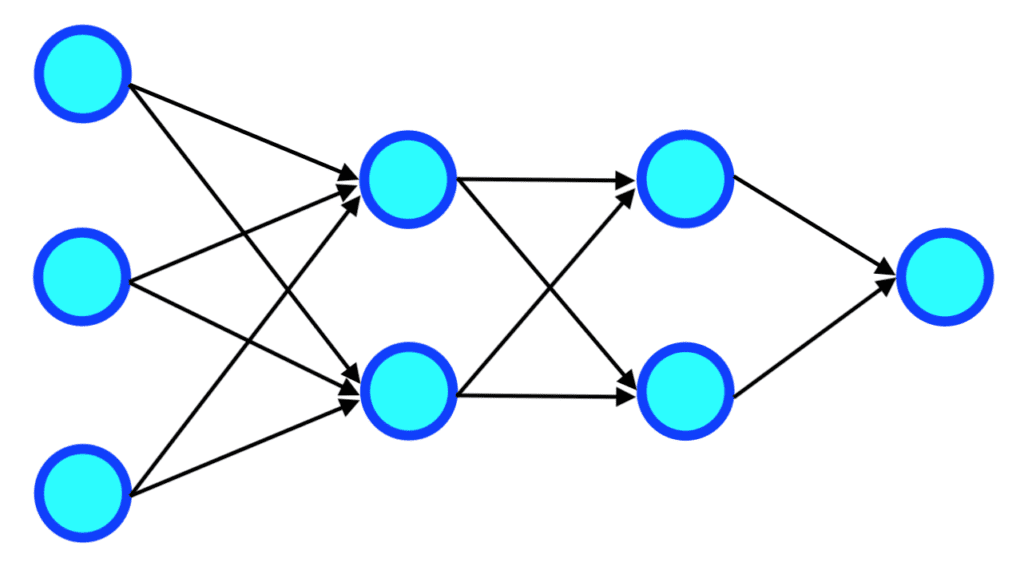
Nei collegamenti tra i neuroni viaggiano le informazioni numeriche di input e di output descritte precedentemente. Questo significa che, fatto salvo per il primo strato (da sinistra), distinto da tutti gli altri e definito “strato di input”, gli input di ciascun neurone sono composti da tutti gli output dei neuroni presenti nello strato immediatamente precedente.
Più precisamente, l’input di ciascun neurone è dato da una somma pesata degli output dei neuroni dello stato precedente, ovvero, considerando i due strati centrali della rete dell’immagine precedente:
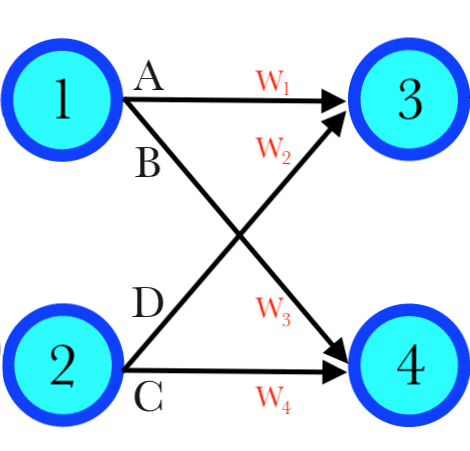
INPUT NEURONE 3: w1A + w2D
INPUT NEURONE 4: w3B + w4C
A ciascuna connessione è associato un peso w diverso il quale, moltiplicato per il valore dell’output, influenza il risultato della somma pesata. È proprio il valore di questi pesi, come vedremo, la chiave del potere di apprendimento della rete neurale.
Immaginiamo ora che la nostra rete neurale sia già stata allenata su un opportuno insieme di dati e sia quindi in grado di restituire il valore di reddito di una persona sulla base delle tre variabili età, peso e numero di scarpe (l’esempio è volutamente semplicistico).
La rete è stata allenata sulla base di un dataset che associa a ciascun valore di reddito l’età, il peso ed il numero di scarpe della persona che lo produce. Marco ha 32 anni, pesa 83 kg e porta il 43. Inserendo in input i valori 32, 83 e 43, una volta effettuati tutti i calcoli lungo le connessioni, la rete restituisce come valore 28.000 euro. Il numero 28.000 ottenuto in output corrisponde quindi con la stima della rete neurale circa il reddito di Marco.
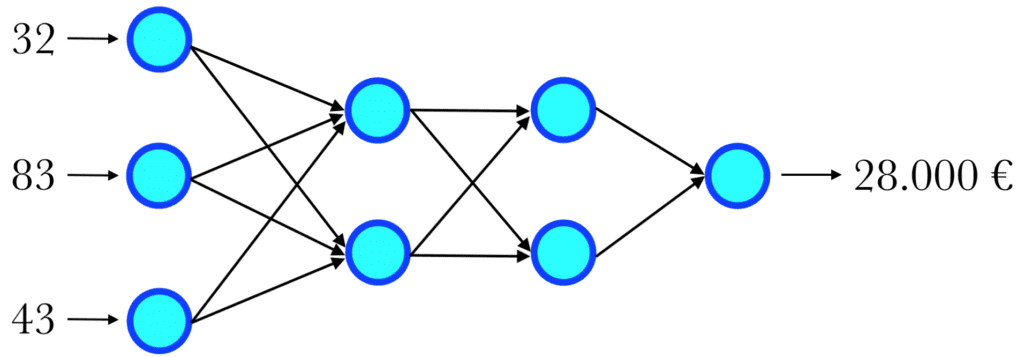
Una volta allenata, a parità di input, una rete neurale restituirà sempre lo stesso output. L’unico obiettivo dell’allenamento è la determinazione opportuna dei pesi w in modo che ad un determinato input corrisponda un output il meno errato possibile.
Ma come avviene l’allenamento? L’allenamento di una rete neurale artificiale avviene secondo un algoritmo noto come “backpropagation”, traducibile in italiano come “retropropagazione” e consistente di una procedura di correzione iterativa del valore dei pesi sulla base di un feedback numerico circa l’errore effettuato dalla rete nell’esecuzione di una stima, esattamente come quella effettuata riguardo il reddito di Marco.
Durante ogni iterazione della procedura di training, dall’insieme di dati utilizzati per allenare la rete vengono prese le informazioni riguardanti uno specifico esempio, come il signor Giovanni, il quale ha 61 anni, pesa 75 kg, porta il 41 e guadagna 62.000 euro l’anno. I pesi situati sulle connessioni della rete neurale, che come abbiamo capito quindi sono gli unici responsabili, una volta inseriti i tre input, del valore dell’output finale (ovvero del reddito della persona), vengono inizializzati con valori casuali all’inizio della procedura di training e man mano aggiustati sulla base dell’errore di stima.
Quando, durante il training, si inseriscono i dati del signor Giovanni, la rete con i pesi non ancora calibrati darà un valore verosimilmente molto errato, come ad esempio 190.000, mentre il reddito del signor Giovanni è di 62.000. Una volta calcolato l’output di 190.000, dunque, si calcola l’errore, in questo caso pari ad una discrepanza di 128.000 euro e si aggiustano i valori dei pesi (partendo dagli strati più a destra e risalendo a ritroso verso gli strati iniziali, per questo si parla di “retro – propagazione”) in modo tale che, se venissero reinseriti gli stessi input riguardanti il signor Giovanni, si otterrebbe un valore di reddito vicino ai 62.000 euro.
Questa procedura viene quindi estesa a tutti gli esempi del dataset utilizzato per il training ed il risultato finale sarà quindi una rete neurale che ha “imparato” a dare una risposta il meno possibile errata circa il reddito di una persona, sulla base delle variabili età, peso e numero di scarpe. Ovviamente, tale conoscenza sarà limitata dalle informazioni presenti all’interno del dataset di training, da qui l’importanza dei dati utilizzati per allenare la rete neurale.
In questo esempio, molto semplificato e inverosimile dal punto di vista pratico (non si può determinare il reddito di una persona semplicemente dall’età, dal peso e dal numero di scarpe), è stata utilizzata per motivi di esposizione una rete neurale “giocattolo” con soli 8 neuroni totali. Nelle applicazioni pratiche si arrivano ad utilizzare reti con decine di migliaia di neuroni su ciascuno strato.