
Benvenuto nella rubrica How It Works!
Come facciamo a riconoscere un cane da un gatto?
Apparentemente questa potrebbe sembrare una domanda banale. Un gatto è molto diverso da un cane. Provando a definire un insieme di regole dettagliate che ne specifichino le differenze, tuttavia, ci si accorgerebbe ben presto che, perché la distinzione sia precisa, queste dovrebbero essere migliaia o forse milioni. Segue un esempio:
– Regola 1: un gatto è più piccolo di un cane.
Pensandoci bene, però, i Chihuahua sono cani generalmente molto piccoli. Bisogna correggere la regola 1.
– Regola 1 (corretta): un gatto, a parte per quanto riguarda i Chihuahua, è più piccolo di un cane.
Come si gestirebbe tuttavia il caso di un Chihuahua particolarmente grande rispetto alla media? Inoltre, sarebbe necessario anche specificare in maniera precisa come si distingue un Chihuahua dagli altri cani. Il numero di regole da definire per coprire tutti i casi sarebbe pressoché infinito.
Come si può intuire da questo semplice esempio, definire in modo preciso come distinguere un cane da un gatto non è un compito risolvibile in questo modo. Non è pensabile codificare le differenze tra cani e gatti in modo preciso solamente tramite la definizione di regole, per quanto dettagliate.
Esistono infiniti cani ed infiniti gatti, non ne esistono né ne sono mai esistiti due uguali, ma allora perché per noi è così semplice distinguere le due specie?
A grandi linee, il motivo risiede nel fatto che il nostro cervello non ragiona secondo regole rigide, bensì approssima nel modo più esaustivo e flessibile il concetto di “gatto”, rendendosi in grado di massimizzare le probabilità di classificare come “gatto” un gatto mai visto prima. Anche la nostra mente, tuttavia, può essere ingannata, come dimostra la seguente immagine (è un gatto o un cane?). Dunque:

I meccanismi secondo i quali opera l’intelligenza artificiale, riconducibili in grandissima parte alla disciplina del Machine Learning, permettono di definire regole talmente complesse da creare l’illusione che sia definita una “idea di gatto” (o di cane) sulla base della quale il software sia in grado di esprimere un giudizio efficace, applicando tale idea in modo generale, rispetto agli infiniti esempi possibili di esemplari della specie. In parole povere, tale complessità riesce ad illuderci del fatto che il software abbia effettivamente imparato “cosa sia, in genere, un gatto” (e se anche il nostro cervello non creasse altro che un’illusione simile?).
L’analogia con il cervello riporta subito ai modelli di Machine Learning in assoluto più utilizzati per il riconoscimento delle immagini, ovvero le reti neurali. In particolare, tuttavia, generalmente non viene utilizzata la rete neurale classica (il cosiddetto “multi-layer perceptron”), bensì una variante detta “rete neurale convoluzionale”.
Si supponga che si voglia creare un software in grado di distinguere se l’immagine fornita in input contenga una stella, un quadrato o un triangolo. Si ipotizzi inoltre che le immagini fornite in input siano disegnate a mano da una persona su un “foglio digitale” usando il mouse.
Trattandosi di una disegno manuale, le forme “quadrato”, “triangolo” e “stella” non saranno “standardizzate”, bensì sempre diverse. Il software dovrà quindi essere in grado di ricondurre tutte le infinite varianti di ciascuna forma ai concetti di “quadrato”, “triangolo” e “stella”.
Ciascuna immagine digitale altro non è che un insieme di pixel; in un’immagine in bianco e nero, ciascun pixel può essere tradotto nell’informazione binaria 1 (nero) o 0 (bianco), come si può vedere di seguito. Dunque:
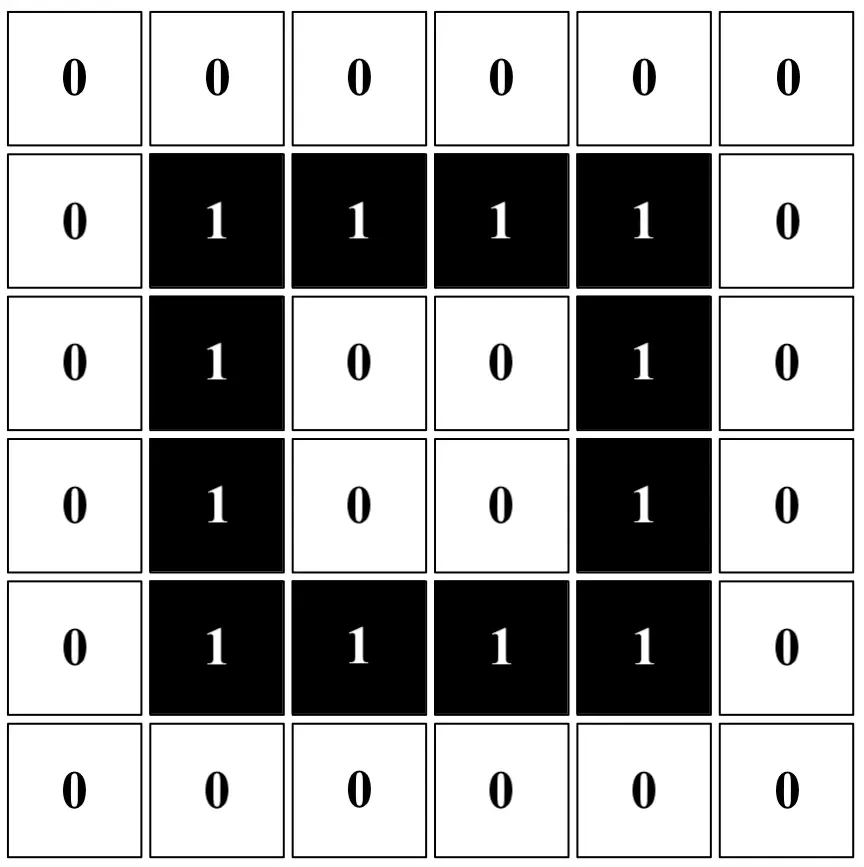
Essendo le immagini in questo caso composte da pochi pixel, si potrebbe ottenere un buon risultato anche solo servendosi di una normale rete neurale agendo come segue. Dunque:
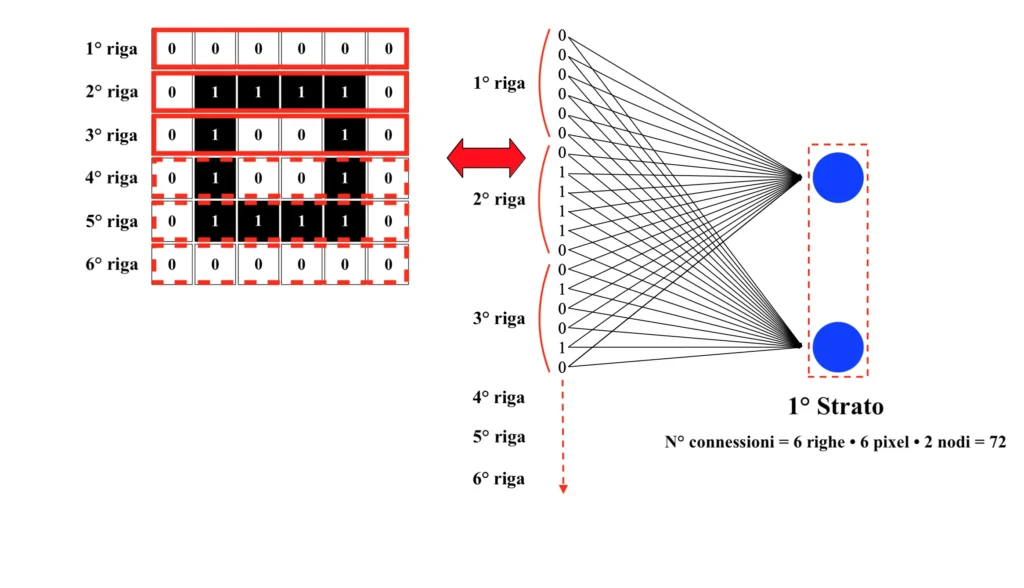
Ciascun pixel contenuto in ciascuna riga del quadrato rappresenta una diversa variabile di input. Il valore di ciascuna variabile dev’essere inserito in tutti i neuroni del primo strato della rete neurale; in corrispondenza di ciascuna connessione sarà presente un parametro da ottimizzare. Disponendo di una rete molto semplice, formata da due neuroni nel primo strato e solamente da un altro layer sul quale giacciono ulteriori due neuroni, si otterrebbero già ben 76 connessioni (delle quali 72 solamente sul primo strato), nonché altrettanti parametri da calibrare durante la fase di addestramento.
Considerando che le immagini scattate da una macchina fotografica moderna sono costituite da milioni di pixel e che le reti neurali utilizzate per applicazioni reali sono costituite da molteplici strati contenenti centinaia o migliaia di neuroni, si può intuire come un approccio di questo genere non sia facilmente scalabile e, di fatto, risulti applicabile a stento ad immagini costituite da una manciata di pixel.
Inoltre, le classiche reti neurali si dimostrano tipicamente poco efficienti nel riconoscere la stessa immagine traslata, anche solo di un singolo pixel, in qualunque direzione. Al fine di ovviare a queste problematiche, può essere sfruttata la particolare architettura delle cosiddette “reti neurali convoluzionali”. Per prima cosa, una rete neurale convoluzionale applica un “filtro” all’immagine di input. Tale filtro altro non è che una matrice di pixel che viene moltiplicata, un quadrante alla volta, con tutti i pixel dell’immagine di input. Dunque:
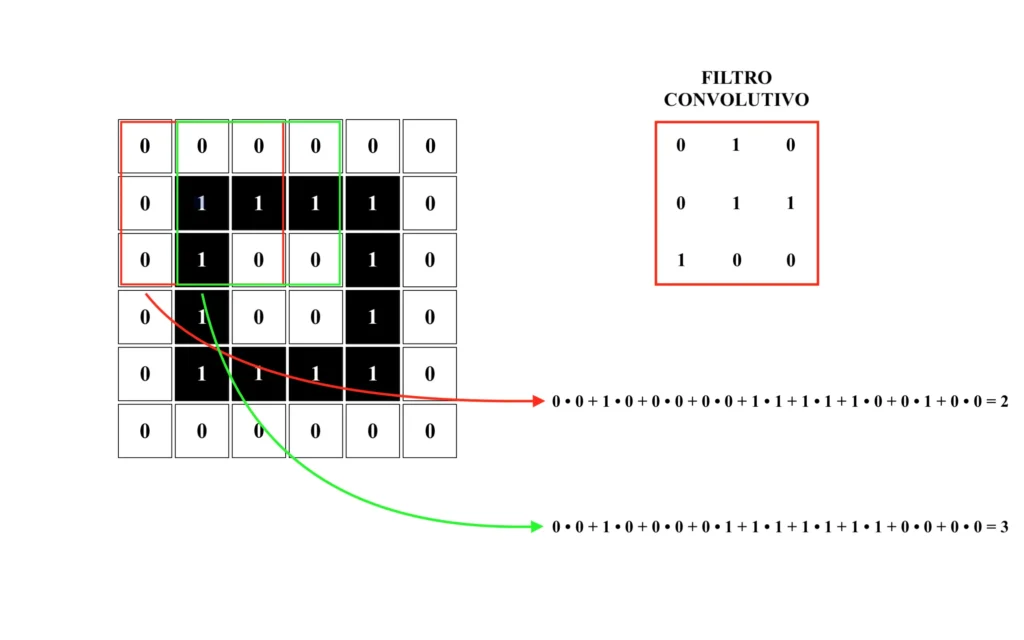
Il risultato, anche detto “feature map”, è il seguente. Dunque:
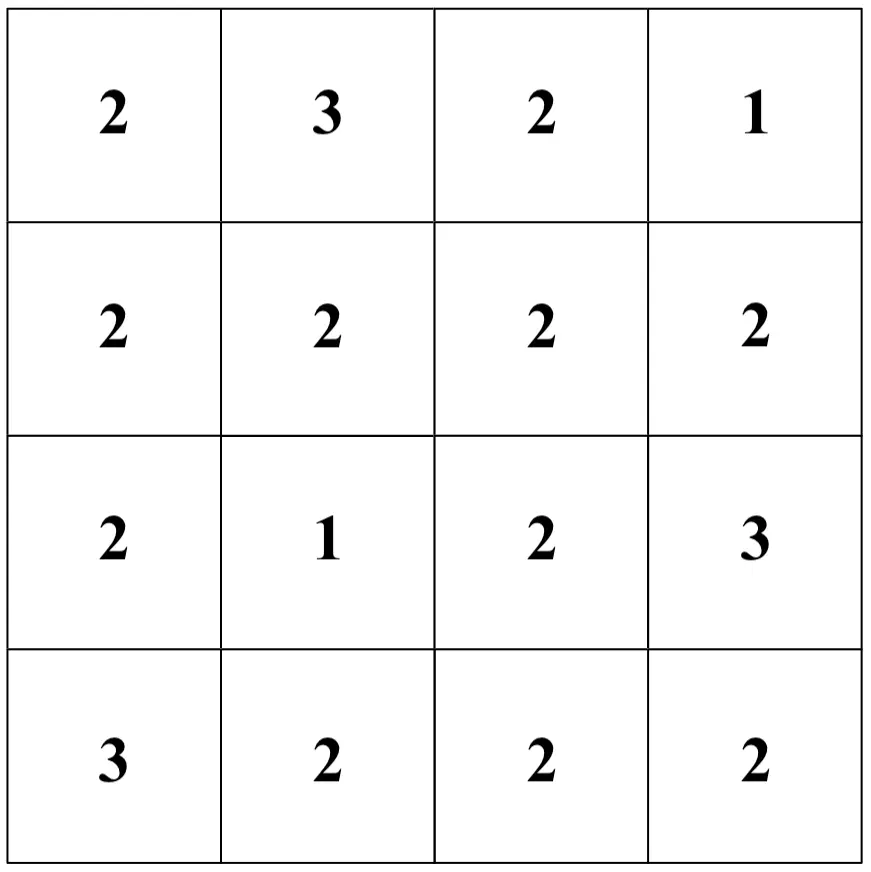
Si è quindi di fatto ridotta l’immagine di input ad una “mappa” riassuntiva delle relazioni di vicinanza tra i pixel originali (secondo la struttura del filtro); tale operazione prende il nome di “convoluzione”.
La struttura del filtro, inizializzata casualmente (in questo caso, con pixel bianchi e neri casuali), viene ottimizzata durante la fase di addestramento della rete. Alla feature map è successivamente sommato un bias il quale, come la struttura del filtro, sarà oggetto di calibrazione durante la procedura di training. Il bias è in questo caso ipotizzato pari a -2. Dunque:
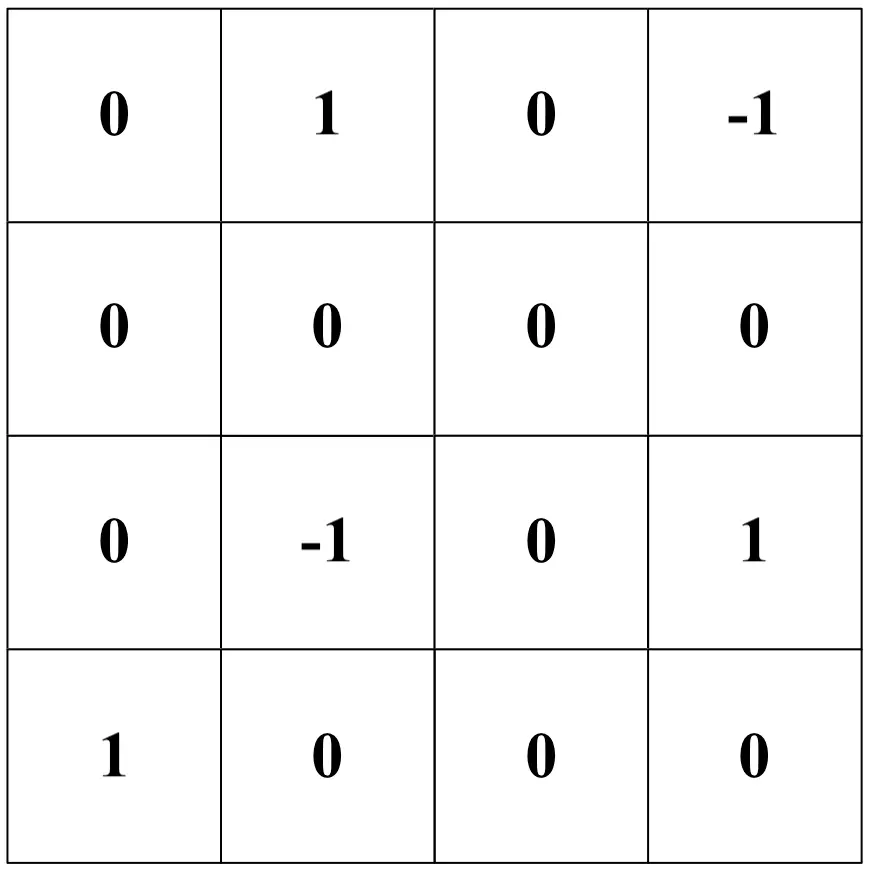
Essendo ciascun valore della “mappa” il frutto di un prodotto scalare che coinvolge pixel limitrofi dell’immagine originale, lo step di convoluzione aiuta la rete neurale a tenere conto delle correlazioni tra ciascun pixel ed i pixel circostanti, offrendo la possibilità di risolvere problemi come quello del riconoscimento d’immagini traslate.
Allo stesso tempo, inoltre, tramite la convoluzione si è ridotto il numero di pixel dell’immagine originale, producendone una decisamente più gestibile.
Dopo la convoluzione, a ciascun valore dell’immagine risultante viene applicata una funzione ReLU (in inglese, Rectifier Linear Unit), la quale azzera i valori negativi e mantiene inalterati quelli positivi. Il risultato sarà quindi il seguente. Dunque:
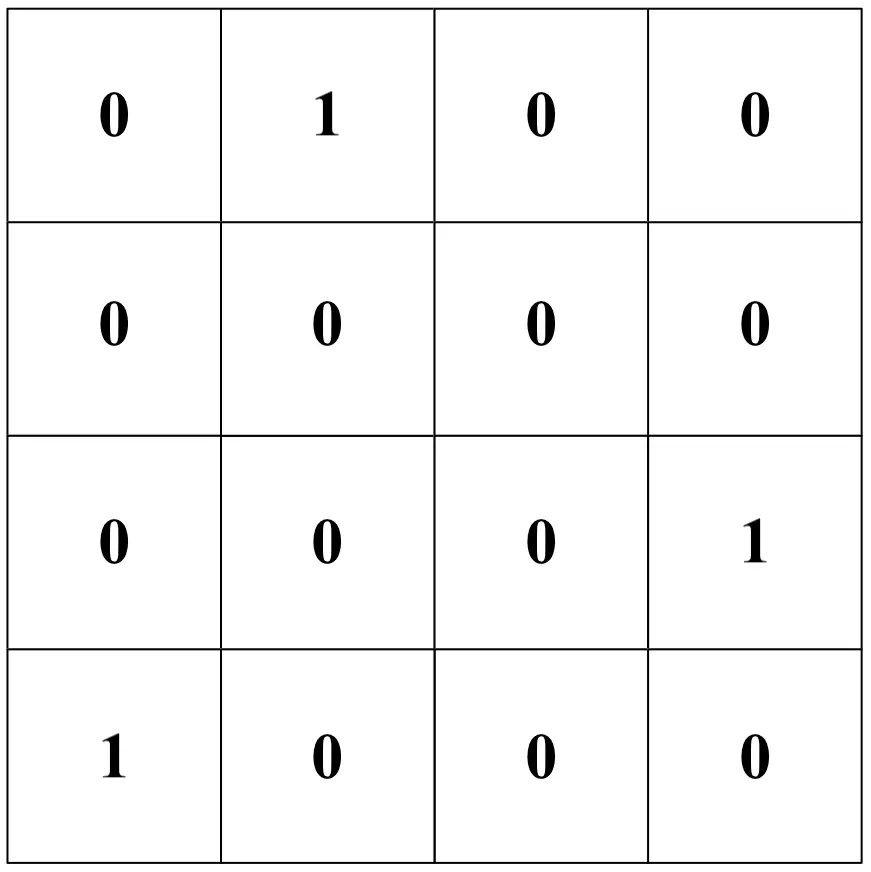
Una volta applicata la funzione ReLU si filtra ulteriormente l’immagine, generalmente utilizzando una matrice la quale seleziona, per ciascun quadrante dell’immagine, il pixel con valore massimo.
Tale procedura è detta “pooling” e, in particolare, se viene utilizzato come filtro quello appena descritto, “max-pooling”. Dunque:
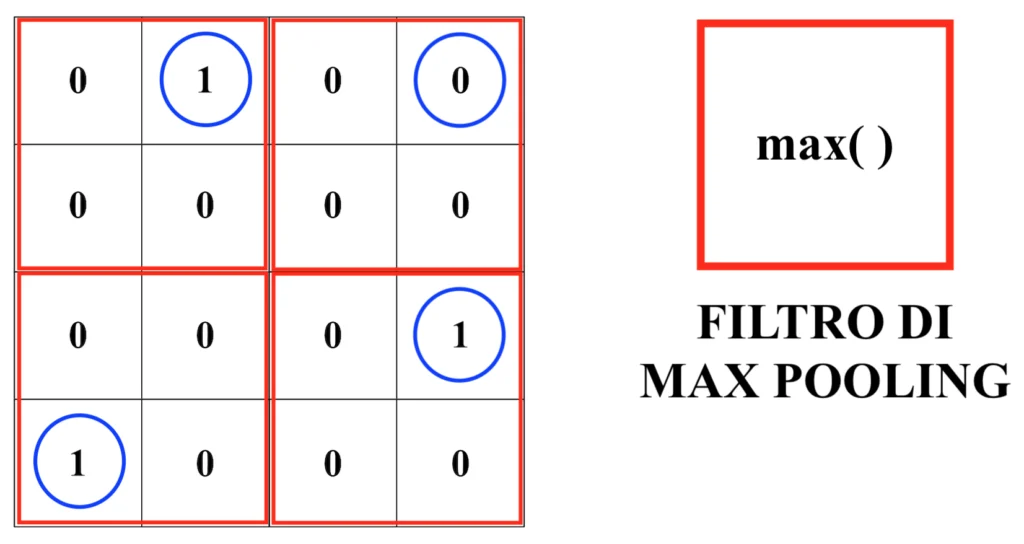
Dopo la procedura di max-pooling l’immagine originale risulterà quindi modificata come segue. Dunque:

Questa versione ulteriormente rimpicciolita può essere ora agevolmente inserita in input, come si era tentato di fare in modo decisamente inefficiente con l’immagine originale, all’interno di una rete neurale tradizionale. Dunque:
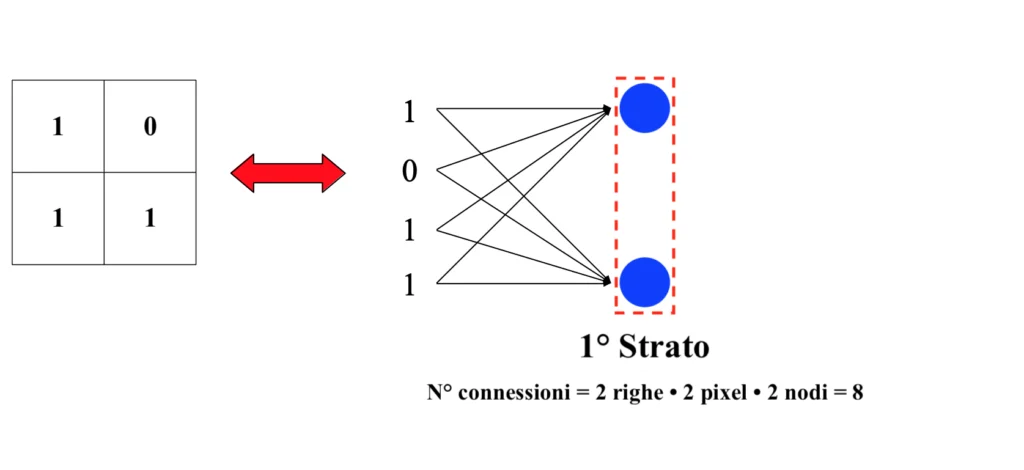
Come si può osservare, il numero di connessioni sul primo strato è stato ridotto da 72 ad 8, rendendo di gran lunga più “leggero” il carico informativo delle immagini da processare.
In questo esempio sono stati utilizzati solamente un filtro convoluzionale ed un filtro di pooling; nelle applicazioni reali, tuttavia, tipicamente si sfruttano architetture più complesse, costituite da più filtri di vario tipo posti in sequenza.
La rete neurale convoluzionale non è quindi altro che un insieme di “strati convoluzionali” (in inglese, “convolutional layers”) e di “pooling” (in inglese, “pooling layers”), dopo i quali viene applicata una normalissima rete neurale “tradizionale” (o, per la precisione, un “multi – layer perceptron”). Una volta quindi ottimizzati tramite la fase di training i filtri di convoluzione, i bias ed i parametri della rete neurale, sarà possibile classificare le immagini inserite in input nelle tre forme “quadrato”, “triangolo” e “stella”, come mostrato di seguito. Dunque:
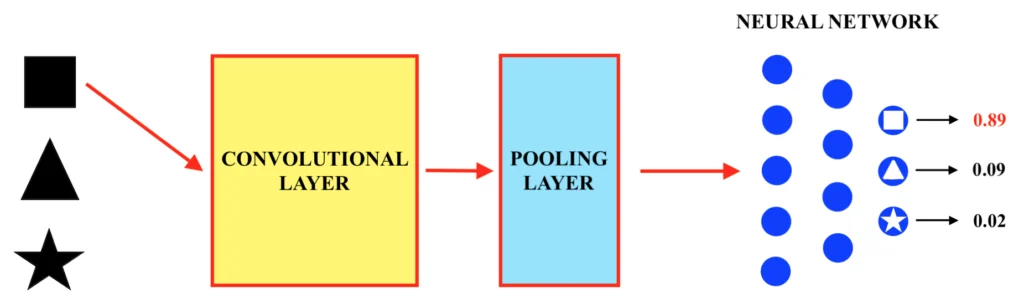
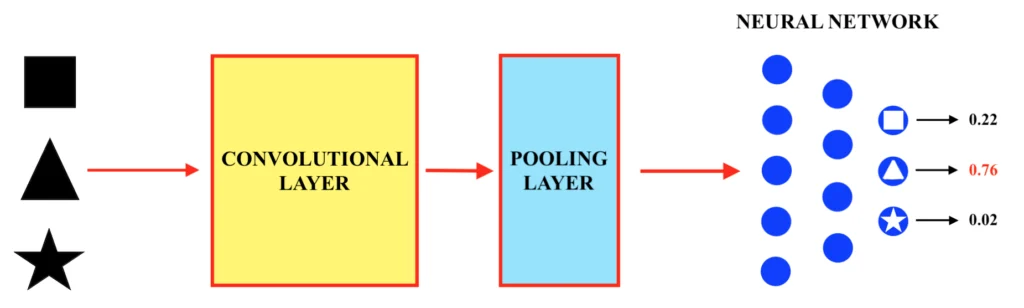
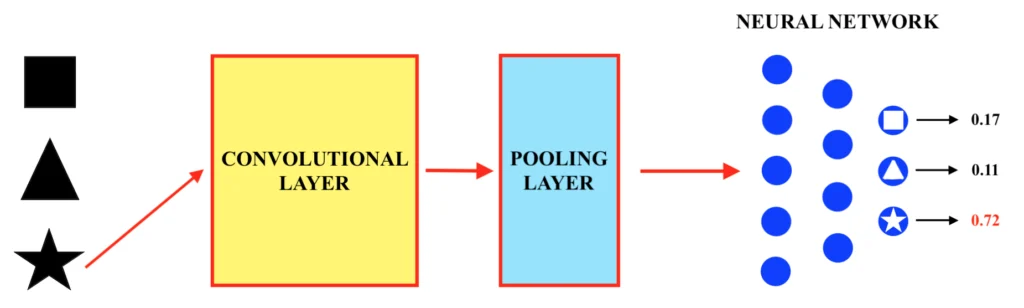
Una volta opportunamente allenata, la rete neurale convoluzionale produrrà, ogni volta che viene inserita al suo interno un’immagine di input da classificare (ovvero da riconoscere), un valore probabilistico circa ciascuna delle tre possibili categorie alla quale questa può appartenere, in questo caso “quadrato”, “triangolo” o “stella”. La categoria alla quale è associato il valore di probabilità più alto consisterà nel risultato della classificazione.
Di fatto, dunque, una rete neurale convoluzionale tende (una volta addestrata a dovere) a “riassumere” le caratteristiche maggiormente rilevanti che permettono di distinguere un’immagine da un’altra, in modo da alleggerire la quantità d’informazioni da processare al fine di realizzare il compito di riconoscimento in modo efficiente. Di seguito è riportato un esempio di convoluzione (e pooling) di un’immagine complessa tramite una rete neurale convoluzionale. Dunque:


La prima immagine è la foto originale, mentre la seconda è l’immagine dopo i processi di convoluzione e di pooling. Anche l’immagine processata, nonostante sia composta da molte meno informazioni (ovvero da molti meno pixel), riporta chiaramente un gatto. Il “riassunto” è stato quindi effettuato in modo efficace, in quanto le informazioni selezionate (si ricordi che il filtro convolutivo, il quale determina come le informazioni vengono “riassunte”, viene ottimizzato durante il training in modo da garantire la massima capacità di classificazione possibile da parte della rete) sono sufficientemente “importanti” per distinguere il contenuto dell’immagine.
Francesco