
Benvenuto nella rubrica How It Works!
Le capacità di “apprendimento” di modelli di Machine Learning dai nomi accattivanti (il “Machine Learning” è la principale disciplina alla base dell’intelligenza artificiale) come ad esempio le “reti neurali” danno spesso la sensazione di essere il frutto di misteriosi procedimenti al limite con la magia. Come si vedrà di seguito, non si tratta di nulla di particolarmente complesso, tanto meno di magico.
Le reti neurali sono utilizzate per effettuare stime e previsioni di vario genere e sono costituite da strati di unità di calcolo chiamate “neuroni”. Ogni neurone riceve un input numerico, lo elabora e restituisce un output. Tali unità di calcolo sono collegate tra loro tramite connessioni “pesate”, ovvero attraverso “ponti” a ciascuno dei quali è associato un valore numerico (detto appunto “peso”) che determina l’importanza attribuita all’input che vi transita rispetto ad un altro. L’output di ciascun neurone diventa l’input del neurone successivo, quindi del successivo, fino all’ultima unità posta sull’ultimo strato della rete, il quale output costituisce il risultato numerico (ovvero la stima o previsione) dell’intera rete neurale (per approfondire la struttura delle reti neurali, leggi qui il nostro articolo sull’argomento!). Nella seguente immagine è riportata una rete neurale ad uno strato (quello composto dai neuroni azzurri); in corrispondenza di ciascuna connessione, in questo caso tra lo strato ed il livello di input e tra lo strato ed il livello di output, sono riportati i pesi w, t e p della rete. Dunque:
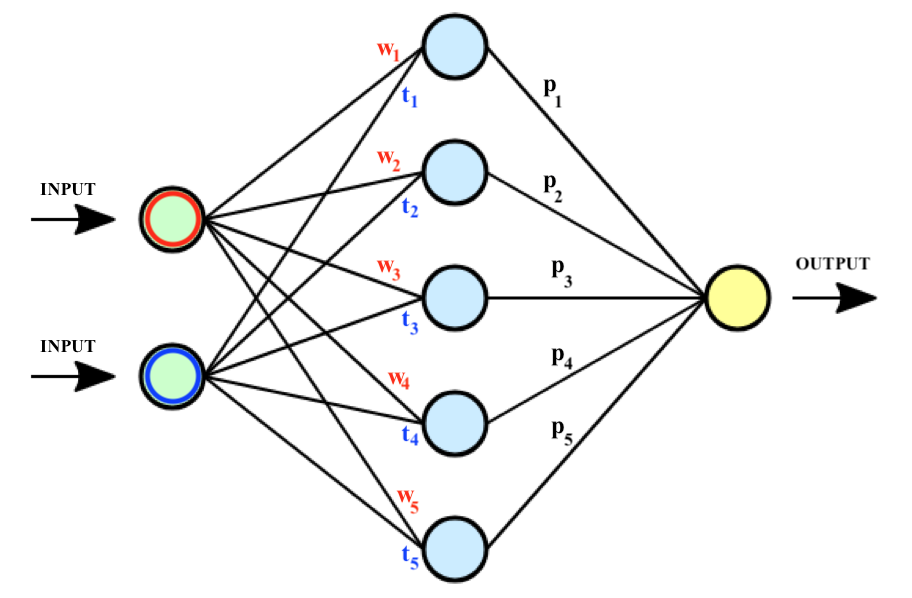
Perché una rete neurale sia in grado di restituire una previsione accurata è necessario “allenarla” utilizzando opportuni dataset (si definisce “dataset” un generico insieme di dati) contenenti dati inerenti l’obiettivo della stima. Ad esempio: se l’obiettivo è stimare il valore di una casa, il dataset conterrà molti esempi di immobili corredati dai valori di alcune variabili ad esse associati, come ad esempio la metratura, la posizione rispetto al centro, il numero di bagni o la presenza del giardino; a ciascuno di questi esempi (si ricorda, contenuti all’interno del dataset utilizzato per l’addestramento della rete neurale) è associato l’effettivo prezzo della casa.
Il processo di addestramento della rete neurale non consiste altro che nella calibrazione dei pesi delle connessioni tra i neuroni in modo da ottenere, una volta inseriti i valori delle variabili di un esempio (ad esempio, la metratura, il numero di bagni, etc. di una casa della quale voglio stimare il valore), una stima accurata come output. Nella seguente immagine è riportato un esempio di stima del prezzo di un immobile, dati i valori delle variabili inserite in input. Dunque:
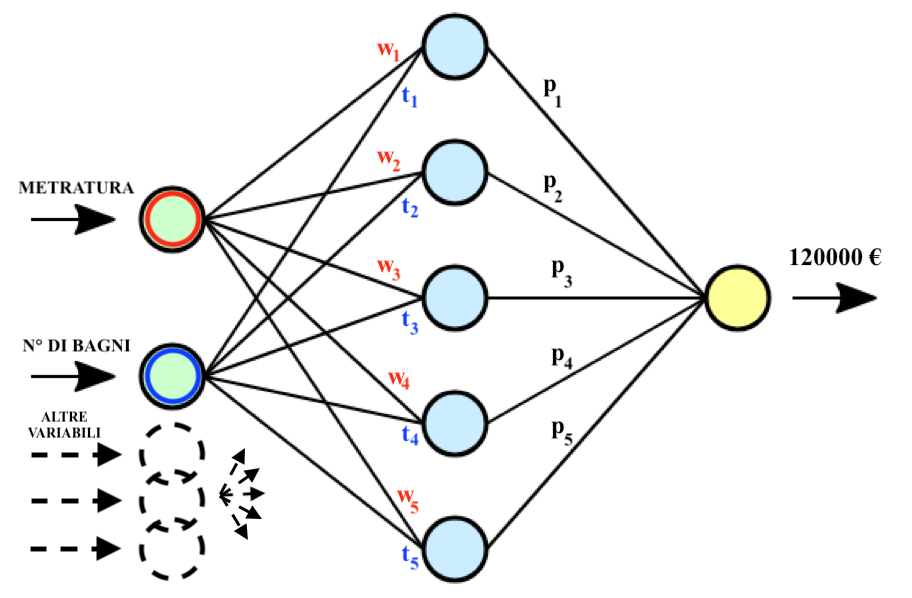
Fatta questa premessa, in cosa consiste la procedura di addestramento della rete neurale?
Prima dell’inizio del processo di addestramento (in inglese, processo di “training”), i pesi della rete sono inizializzati con valori casuali; questo significa che, inizialmente, le previsioni della rete sono sicuramente del tutto imprecise.
Durante il training la rete neurale è sottoposta ad un processo iterativo di calibrazione dei pesi, il quale prende il nome di “backpropagation algorithm” (in italiano, “algoritmo di retropropagazione”); durante questo processo la rete effettua ripetute previsioni sulla base dei dati del dataset di training, ricevendo correttivi in base all’accuratezza di tali stime.
Ipotizzando di voler creare una rete neurale in grado di stimare correttamente il prezzo di un’abitazione, all’inizio della procedura di training le stime saranno quindi sicuramente, nel complesso, gravemente errate (in quanto i pesi sono inizializzati completamente a caso). L’errore relativo a ciascuna previsione viene misurato da una cosiddetta “funzione di perdita” (in inglese, “loss function”), la quale può essere pensata come una sorta di “voto” che la rete riceve per la sua previsione. Più l’errore di stima è grande, peggiore è il voto.
Una volta ricevuto il voto, i pesi della rete vengono ricalibrati (partendo dagli ultimi, ovvero dai pesi più vicini allo strato di output della rete, a risalire verso i neuroni di input; per questo motivo si parla di “retropropagazione”), in modo da aggiustare le capacità di stima della rete alla luce dell’errore appena compiuto.
L’esatto valore della casa era 100.000 € e la rete ha stimato un valore pari a 120.000 €? Una volta aggiustati i pesi, eseguendo nuovamente la stessa stima sulla medesima abitazione l’errore sarà senz’altro di entità minore. Nella seguente immagine è riportata una schematizzazione della procedura di “correzione a ritroso” del valore dei pesi sulla base dell’errore di stima. Dunque:
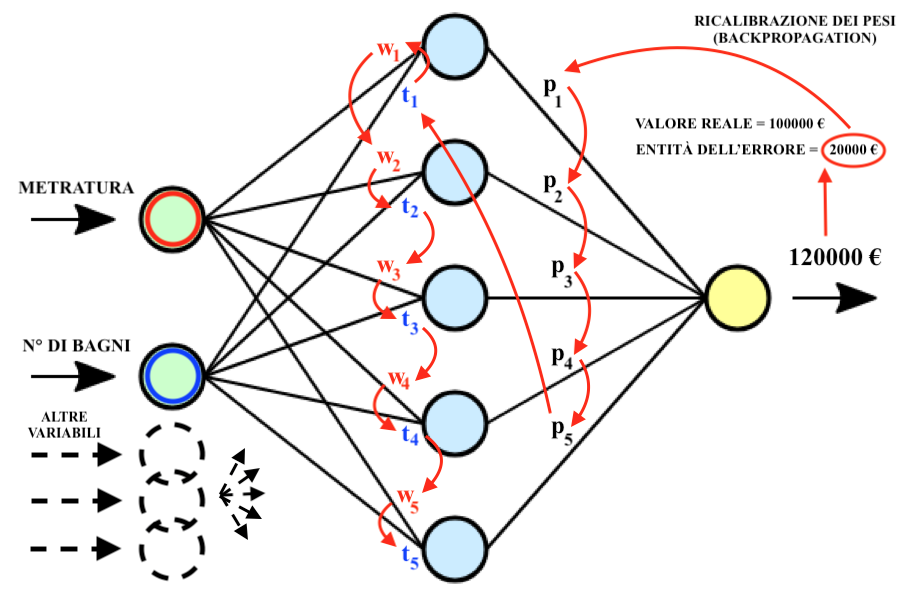
La rete non deve tuttavia essere in grado di stimare il prezzo di vendita di una sola specifica abitazione, bensì delle abitazioni in generale. Ogni ricalibrazione dei pesi effettuata dall’algoritmo di backpropagation tende ad aggiustare la stima rispetto all’esempio corrente, tipicamente riducendo allo stesso tempo le capacità di stima della rete rispetto ad altri esempi di case già esaminati in precedenza durante il training.
Una buona metafora è quella della “coperta corta”: una coperta corta non può coprire tutto il corpo, tuttavia esiste una posizionamento della coperta in grado di “coprire il corpo al meglio delle sue possibilità”.

Questa metafora ricalca perfettamente l’essenza della procedura di training di una rete neurale (e dei modelli di Machine Learning in generale); la rete non sarà mai in grado di prevedere alla perfezione il prezzo di tutti i possibili (infiniti) esempi di case, ma esisterà sicuramente una combinazione dei pesi della rete in grado di restituire la miglior performance previsionale media.
La procedura di addestramento delle reti neurali può quindi essere schematizzata come segue. Dunque:
STEP 1: inizializzazione casuale dei pesi della rete
STEP 2: inserimento nella rete dei valori delle variabili di un esempio tratto dal dataset di training
STEP 3: produzione di una stima sulla base dell’elaborazione di questi valori di input
STEP 4: valutazione della stima tramite la funzione d’errore
STEP 5: aggiustamento dei pesi, partendo da quelli più vicini all’output della rete e procedendo a ritroso, in modo da avvicinare, a parità di input, il valore della stima all’effettivo valore associato all’esempio di training (tornando all’esempio della casa, dunque, in modo da associare il prezzo stimato dalla rete neurale al reale prezzo della casa contenuta all’interno del dataset di addestramento).
STEP 6: si riparte dallo STEP 2 fintanto che non viene raggiunta una specifica condizione di terminazione (la natura della condizione di terminazione verrà discussa in futuri articoli sull’argomento!).
Come hai potuto constatare, le capacità previsionali delle reti neurali non provengono da nessun procedimento “magico”, bensì semplicemente da una rigorosa procedura algoritmica.
Francesco