
Benvenuto nella rubrica Tech Explained!
Lo sviluppo di intelligenza artificiale è economicamente molto dispendioso, ormai è di dominio pubblico. Le voci di costo principali per le aziende che decidono d’investire in questo ramo consistono principalmente nella manodopera specializzata (ingegneri informatici, matematici e accademici di vario genere) e nelle risorse hardware, ovvero nei computer.
Come già abbiamo accennato in un precedente articolo, le grandi multinazionali della tecnologia come Google, Meta, IBM o Microsoft, da decenni stanno progressivamente investendo cifre sempre maggiori per la costruzione di super – computer.
La corsa allo sviluppo delle migliori soluzioni di AI passa infatti in larga parte per la potenza di calcolo a disposizione, la quale per le più grandi realtà ha raggiunto ormai proporzioni immense. Ma cosa s’intende nello specifico per “potenza di calcolo”?
In ambito informatico, la potenza di calcolo di un computer è definita come segue:
“[…] numero di istruzioni che il calcolatore è in grado di eseguire in un secondo, misurata normalmente in milioni di istruzioni al secondo (MIPS)”.
Enciclopedia Treccani
Il principale responsabile della potenza di calcolo di un computer è la “Central Processing Unit” (CPU), in italiano definita semplicemente “processore”. La CPU (nell’immagine sotto, un esempio di CPU) è suddivisa in più unità indipendenti, i cosiddetti “core”, ciascuna in grado di eseguire indipendentemente calcoli in modo sequenziale (ovvero un calcolo dopo l’altro).

Maggiore è la velocità con la quale ciascuna unità (ciascun “core”) è in grado di eseguire le sequenze di calcoli, maggiore è la potenza di calcolo espressa dal computer nel complesso.
Per comprendere l’entità del divario in termini di potenza di calcolo tra un comune computer commerciale ed i più potenti super – computer, consideriamo il seguente confronto. Dunque:
- Computer commerciale con processore Intel Core i9-14900KF 3.20 GHz
- MIPS (stima): 76000 (76 miliardi di istruzioni al secondo)
- Frontier – Oak Ridge National Laboratory (USA)
- MIPS (stima): 26 099 712 000 (26 miliardi di milioni di milioni di istruzioni al secondo)
Il super – computer americano “Frontier”, il più potente super – computer di sempre, è quindi approssimativamente 342 105 volte più veloce di un processore commerciale di ultima generazione.
Questo significa che un compito che il super computer può eseguire in un’ora richiederebbe al computer commerciale circa 39 anni. Questo è il divario.
Il Machine Learning è quindi solamente appannaggio delle grandi aziende tecnologiche, mentre noi comuni mortali dovremmo rassegnarci a giocare con i Lego? Nì.
Sebbene infatti certi esperimenti ed applicazioni siano assolutamente inaccessibili per singoli individui e piccole software house (per intenderci, l’addestramento di chatGPT pare abbia richiesto mesi di esecuzione sul super – computer di proprietà di OpenAI), non tutte le soluzioni di ML che possano portare ad una qualche applicazione utile in questo ambito richiedono una tale immensa quantità di calcoli e molto si può fare sul design dei modelli matematici utilizzati.
Inoltre, esistono soluzioni per accelerare notevolmente la velocità di esecuzione dei comuni computer commerciali. Uno dei principali “trucchi” consiste nell’utilizzare le “Graphics Processing Unit” (GPU), in italiano comunemente chiamate “schede grafiche”, per eseguire più velocemente i calcoli normalmente destinati alla CPU.
Tutti i computer sono dotati di una GPU (nell’immagine seguente si può vedere un esempio di GPU installabile in un computer fisso) ed il motivo è presto detto: serve per mostrare le immagini sullo schermo.

Contrariamente alle CPU, il quale design è finalizzato al calcolo sequenziale (un’istruzione dopo l’altra), le GPU hanno una struttura pensata per far fronte a grandi moli di calcolo in parallelo (ovvero simultaneamente). Il motivo di tale struttura risiede nella necessità, per proiettare al meglio le immagini sullo schermo del computer, di effettuare simultaneamente una grande quantità di operazioni sui milioni di pixel che le compongono (come calcolare ombreggiature, prospettive, colori, effettuare rotazioni, traslazioni, etc.).
Le GPU quindi, diversamente dalle CPU le quali hanno generalmente (nelle configurazioni commerciali) un massimo di 16 core, ne contano migliaia, ciascuno dei quali meno potente rispetto a quelli delle CPU. Essendo i core indipendenti tra loro, consentono il calcolo in parallelo, rendendo le GPU in grado di svolgere un notevole numero di operazioni simultaneamente.
Molti dei calcoli di cui necessitano le applicazioni di Machine Learning sono scomponibili in calcoli più semplici ed eseguibili in modo indipendente l’uno dall’altro. Per questo motivo le GPU costituiscono un’ottima soluzione per velocizzare le spesso interminabili procedure di training!
Allenare un modello di Machine Learning sfruttando le potenzialità di una o più GPU può diminuire di moltissimo i tempi rispetto al solo utilizzo della CPU, rendendo così il divario con i super – computer un po’ meno spaventoso.
La principale azienda produttrice di GPU è NVIDIA. Nella seguente immagine possiamo vedere la crescita della sua quotazione al NASDAQ.
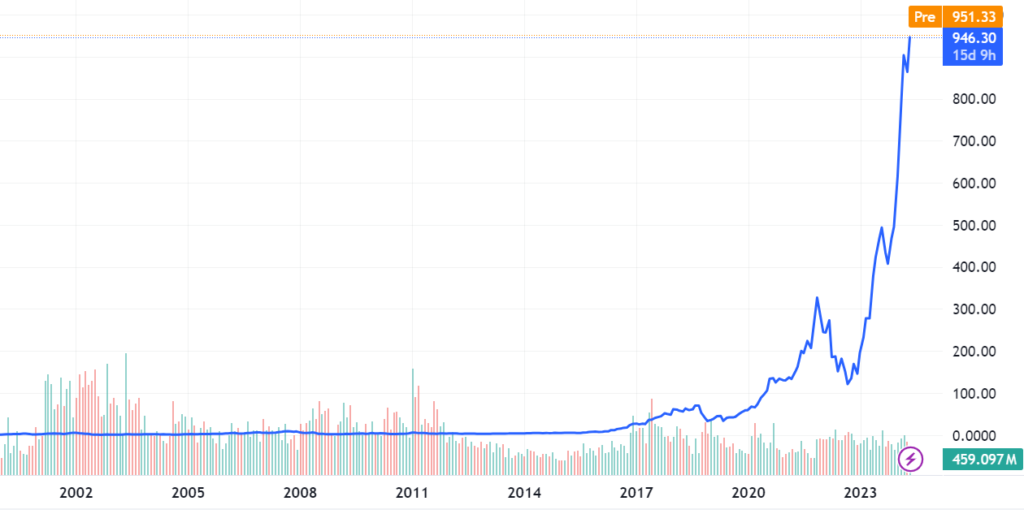
Certo, negli ultimi anni anche l’industria dei videogiochi (per i quali si fa largo uso delle GPU) è cresciuta molto, ma tale crescita non giustifica l’impennata di valore di aziende come NVIDIA.
Durante il primo ventennio degli anni 2000 gli esperti hanno profetizzato a lungo a proposito dell’imminente esplosione dell’intelligenza artificiale (a tal proposito, consiglio caldamente il libro “Superintellgence” di Nick Bostrom, datato 2014); questo grafico sembrerebbe dare loro ragione.
Francesco