
Benvenuto nella rubrica How It Works!
I computer non comprendono direttamente il testo in formato linguistico come fanno gli esseri umani. Per poter essere utilizzato all’interno di modelli di Machine Learning (il Machine Learning è la principale disciplina alla base dell’intelligenza artificiale) un file testuale deve essere tradotto in numeri, l’unica forma di dato che i modelli matematici possono gestire. Tuttavia, la rappresentazione numerica deve essere tale da preservare il significato semantico delle parole e le relazioni tra esse.
Il word embedding è una tecnica utilizzata per rappresentare le parole in uno spazio numerico affinché possano essere interpretate e utilizzate da modelli di Machine Learning come i Large Language Models (non hai mai sentito parlare dei Large Language Models? Leggi il nostro articolo sull’argomento!). Questo processo consiste nel convertire il testo in vettori di numeri reali che preservino le relazioni semantiche tra le parole. Tramite il word embedding si crea dunque una rappresentazione delle parole in uno spazio vettoriale nel quale vocaboli simili vengono mappati in punti vicini tra loro. Di seguito si vedrà nel dettaglio come tale pratica venga eseguita sfruttando un classico modello di Machine Learning: le reti neurali (non hai mai sentito parlare di reti neurali? Leggi il nostro articolo sull’argomento!).
Un modo semplice ed immediato tramite il quale convertire le parole in numeri consiste nell’assegnare a ciascuna parola un numero casuale. Ad esempio, si consideri la seguente frase:
Oggi è una bella giornata
A ciascuna parola può essere assegnato un numero casuale, ad esempio:
Oggi = 12, è = 2, una = -1.2, bella = -11.7, giornata = 40
Si consideri ora la seguente frase, del tutto simile alla precedente:
Oggi è una giornata magnifica
I numeri assegnati alle prime quattro parole saranno i medesimi e poi si assegnerà un ulteriore numero casuale alla nuova parola “magnifica”. Dunque:
Oggi = 12, è = 2, una = -1.2, giornata = 40, magnifica = 32.7
In linea teorica, questo approccio per tradurre le parole in numeri sembrerebbe essere efficace. Tuttavia, procedendo in questo modo, nonostante le parole “bella” e “magnifica” abbiano significati del tutto simili e siano utilizzate con la stessa finalità (ovvero comunicare che la giornata di oggi è “piacevole”), rischiano di essere assegnate a numeri molto distanti tra loro.
In questo caso, essendo assegnato un solo numero a ciascuna parola, la rappresentazione numerica avviene in uno spazio vettoriale mono-dimensionale, di fatto una retta. Dunque:

Come si può vedere, le parole “bella” e “magnifica”, le quali dovrebbero essere vicine nello spazio numerico, sono invece relativamente distanti.
Volendo insegnare ad una rete neurale a prevedere, in base al contesto ed alle parole precedenti, la parola successiva (meccanismo, questo, alla base del funzionamento dei Large Language Models; ancora una volta, se tutto ti sembra incomprensibile leggi il nostro articolo sull’argomento!), ovvero volendo insegnare ad una rete neurale a rispondere ad un input testuale in modo coerente, l’assegnare a parole simili numeri tra loro distanti finirebbe per rendere necessaria, durante la fase di training, molta più complessità (nel caso delle reti neurali, si fa riferimento alla “complessità” della rete in rapporto al numero di strati, nodi e connessioni); in linea di massima, serve una rete neurale molto complessa per gestire correttamente parole simili alle quali sono stati assegnati valori numerici tra loro distanti.
Sarebbe quindi utile riuscire ad associare numeri “simili” a parole simili; in questo modo, per una rete neurale, imparare come utilizzare una parola aiuterebbe ad imparare come utilizzarne un’altra simile. Inoltre, dato che la stessa parola può essere utilizzata in contesti diversi, o ad esempio cambiata al plurale o utilizzata in qualche modo particolare (ad esempio, citata tra virgolette fuori dai suoi contesti abituali), sarebbe ancora meglio potervi assegnare più di un singolo numero, ovvero un vettore di valori reali. Per esempio, la parola “bella” può essere utilizzata in contesti del tutto simili ma con significati opposti:
Oggi è una bella giornata
Oggi è proprio una bella giornataccia
Al fine di dimostrare come una semplice rete neurale sia in grado di ricavare i vettori numerici da associare a ciascuna parola, si immagini di disporre delle seguenti due frasi a titolo di dataset di training:
Oggi è una bella giornata
Oggi è una giornata magnifica
In questo caso si hanno sei diverse parole nell’intero dataset di training; di conseguenza, la rete neurale da costruire per eseguire il word embedding dovrà necessariamente avere sei nodi di input. Dunque:
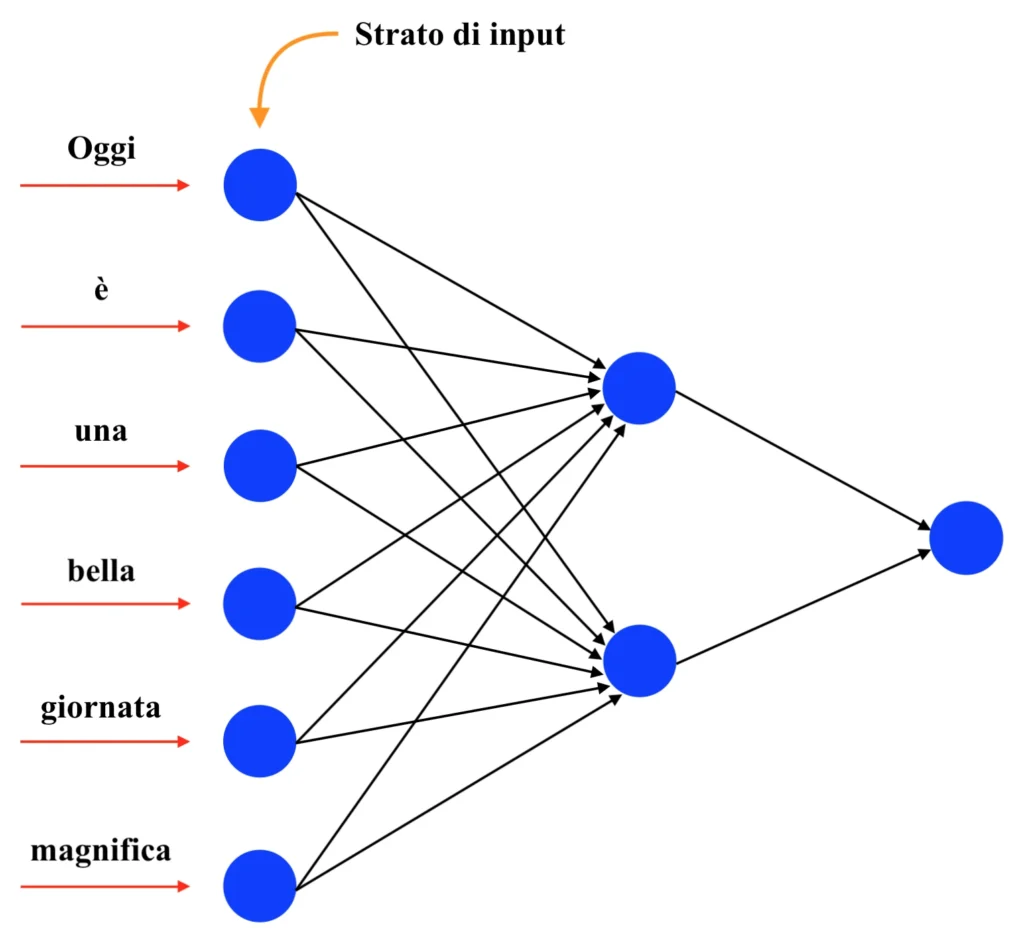
Nel primo strato si avrà un numero di neuroni (i quali avranno tutti come funzione di attivazione la semplice funzione identità, di fatto restituendo quindi in output la somma della combinazione lineare in ingresso) pari al numero di valori numerici che si vogliono associare a ciascuna parola (ovvero pari alla lunghezza del vettore che si vuole associare a ciascuna parola). Dunque:

Tali numeri non sono altro che i pesi associati a ciascuna connessione della rete. Dunque:
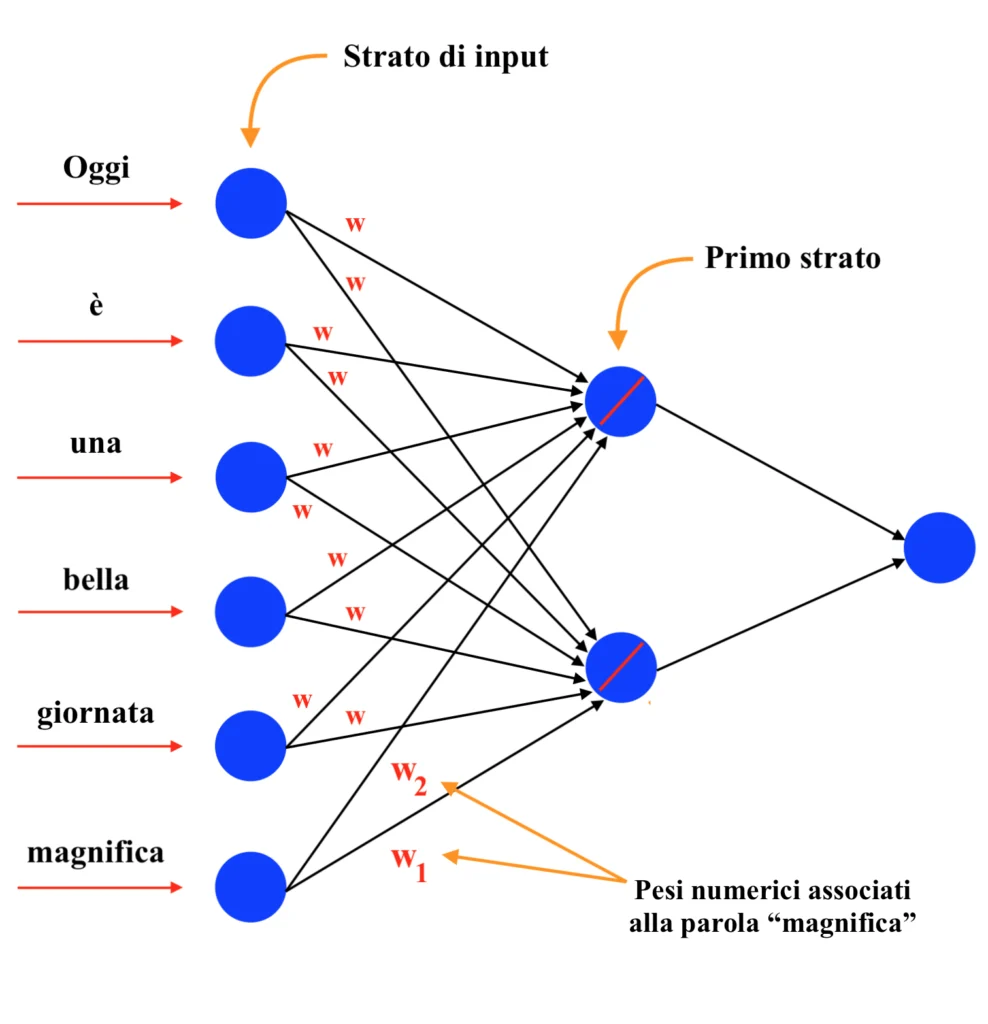
In questo caso, a ciascuna parola è associato un vettore contenente solamente due valori numerici, in quanto la rete neurale ha due neuroni situati sul primo strato. Come avviene sempre nell’ambito della procedura di training delle reti neurali (non hai idea di come avviene la procedura di training delle reti neurali? Leggi il nostro articolo sull’argomento!), inizialmente i pesi sono definiti in modo casuale, per poi essere ottimizzati durante l’algoritmo di backpropagation. Ovviamente, perché possa essere sfruttato l’algoritmo di backpropagation e, in generale, perché una rete neurale possa essere “allenata”, è necessario effettuare delle previsioni (durante la procedura di training). Durante l’addestramento si utilizzano quindi le parole fornite in input alla rete per ottenere, come previsione, la parola successiva della frase.
Se il dataset di training consiste nelle parole “Oggi”, “è”, “una”, “bella”, “giornata”, “magnifica”, durante l’addestramento la rete imparerà a prevedere la parola “è” dopo la parola “Oggi”, la parola “giornata” dopo la parola “bella” e così via. Ipotizzando quindi di inserire come input la parola “Oggi” (inserendo un vettore avente valore 1 in corrispondenza della posizione assegnata alla parola “Oggi” e 0 in tutte le altre posizioni; tale approccio di codifica dell’input prende il nome di “one-hot encoding” e verrà approfondito in un futuro articolo, quindi resta sintonizzato!), ci si aspetta di ottenere come output, una volta allenata la rete su questo “mini-training dataset”, il maggiore valore probabilistico in corrispondenza della parola “è”. Dunque:
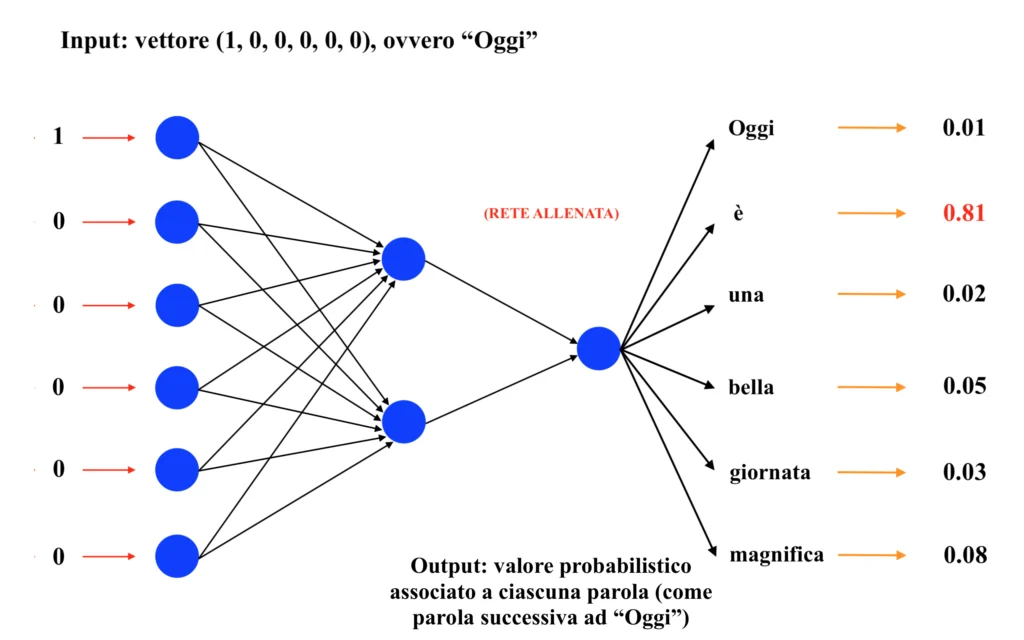
Allo stesso modo, una volta allenata la rete, inserendo come input la parola “bella”, ci si aspetterà di ottenere come output la parola “giornata”. Dunque:
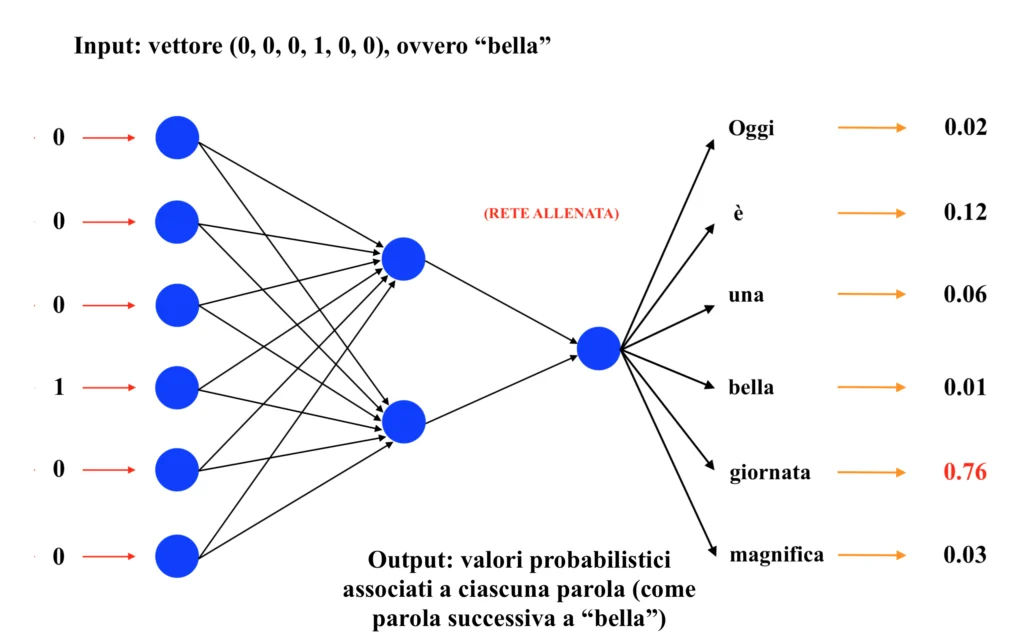
Infine, inserendo in input la parola “magnifica”, ci si aspetterà di ottenere come output ancora una volta la parola “giornata”. Dunque:
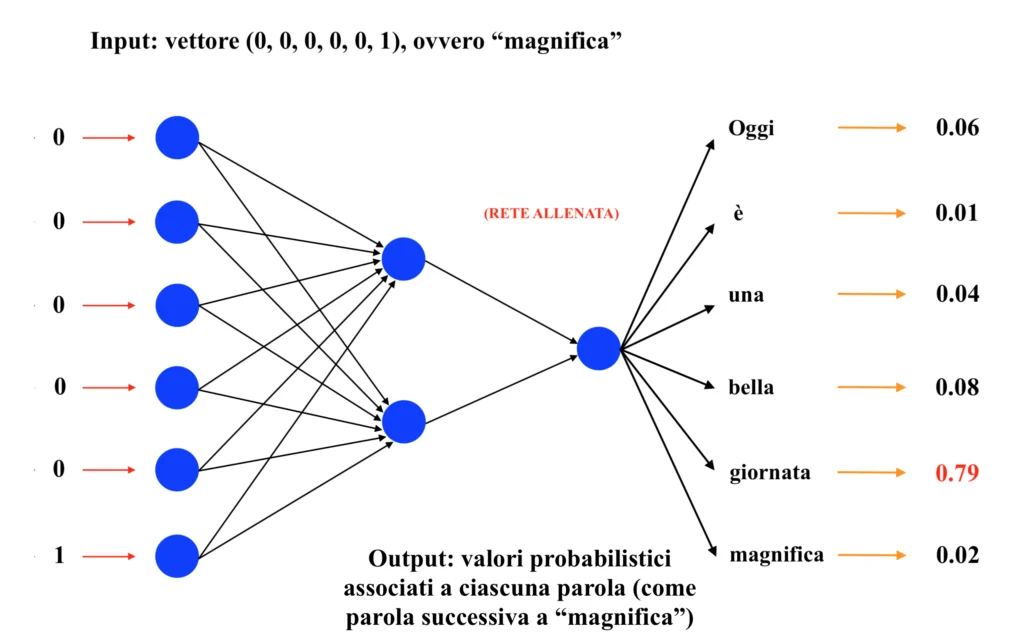
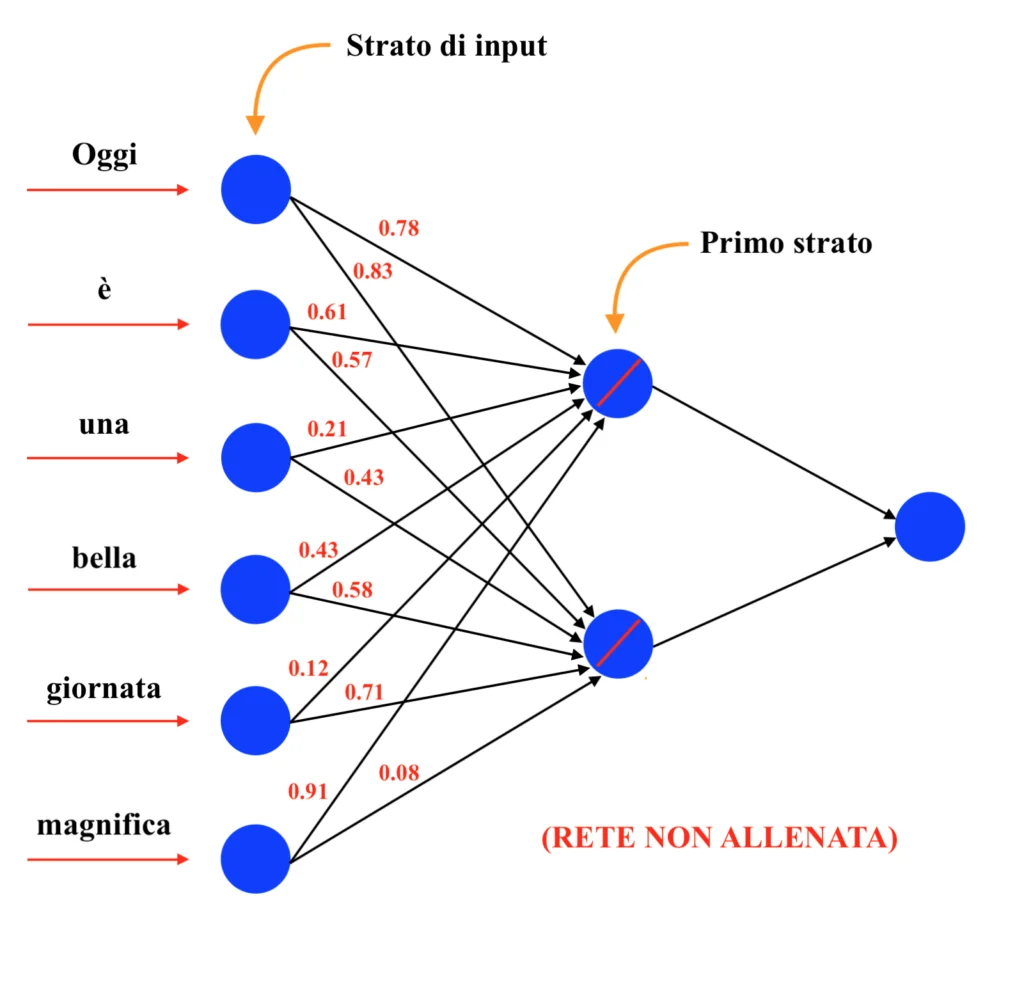
Ricordando che l’obiettivo finale del word embedding è creare vettori in grado di rappresentare efficacemente le parole all’interno di uno spazio vettoriale, in modo da poter poi utilizzare questi vettori all’interno di un ulteriore modello (ad esempio, una rete neurale transformer; a tal proposito, leggi il nostro articolo sugli LLMs!) in grado di sviluppare la capacità di prevedere, partendo da una parola ed in base ad un contesto precedente più o meno ampio, ogni volta la parola successiva (e di fatto “imparare a parlare”), si consideri la rete neurale dell’esempio prima dell’addestramento, ovvero con i pesi ancora inizializzati casualmente:
Essendo in questo caso i vettori associati a ciascuna parola binari, è possibile individuare le parole in uno spazio vettoriale a due sole dimensioni, ovvero in un semplice diagramma cartesiano.
Nel diagramma, alle ascisse sono presenti i pesi relativi alle connessioni che terminano nel primo neurone del primo strato, mentre alle ordinate sono riportati i valori dei pesi relativi alle connessioni che terminano nel secondo neurone del primo strato; ad esempio, la parola “Oggi” sarà individuata nel punto (x, y) = (0.78, 0.83). Dunque:
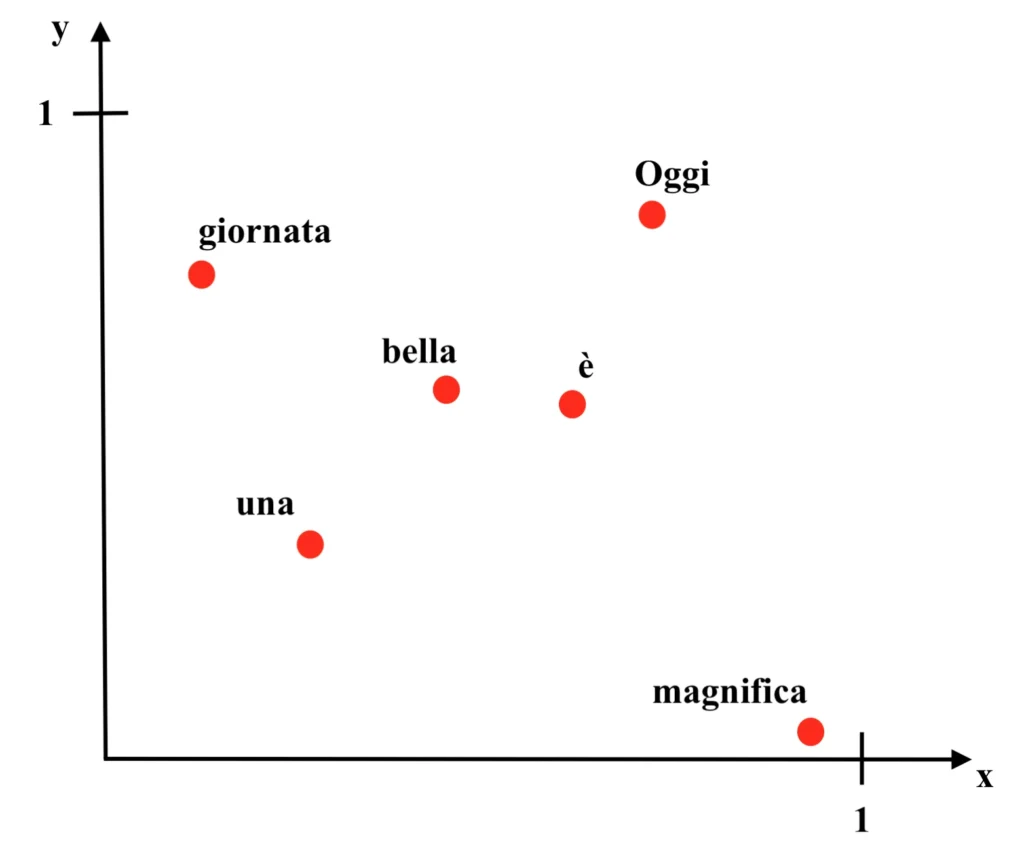
Come si può vedere dall’immagine, malgrado le parole “bella” e “magnifica” siano concettualmente affini e compaiano in modo simile all’interno del contesto, prima che i pesi della rete siano calibrati attraverso la procedura di addestramento le due parole si troveranno distanti all’interno del diagramma. Di seguito si può vedere la rete allenata e il relativo diagramma dei pesi. Dunque:
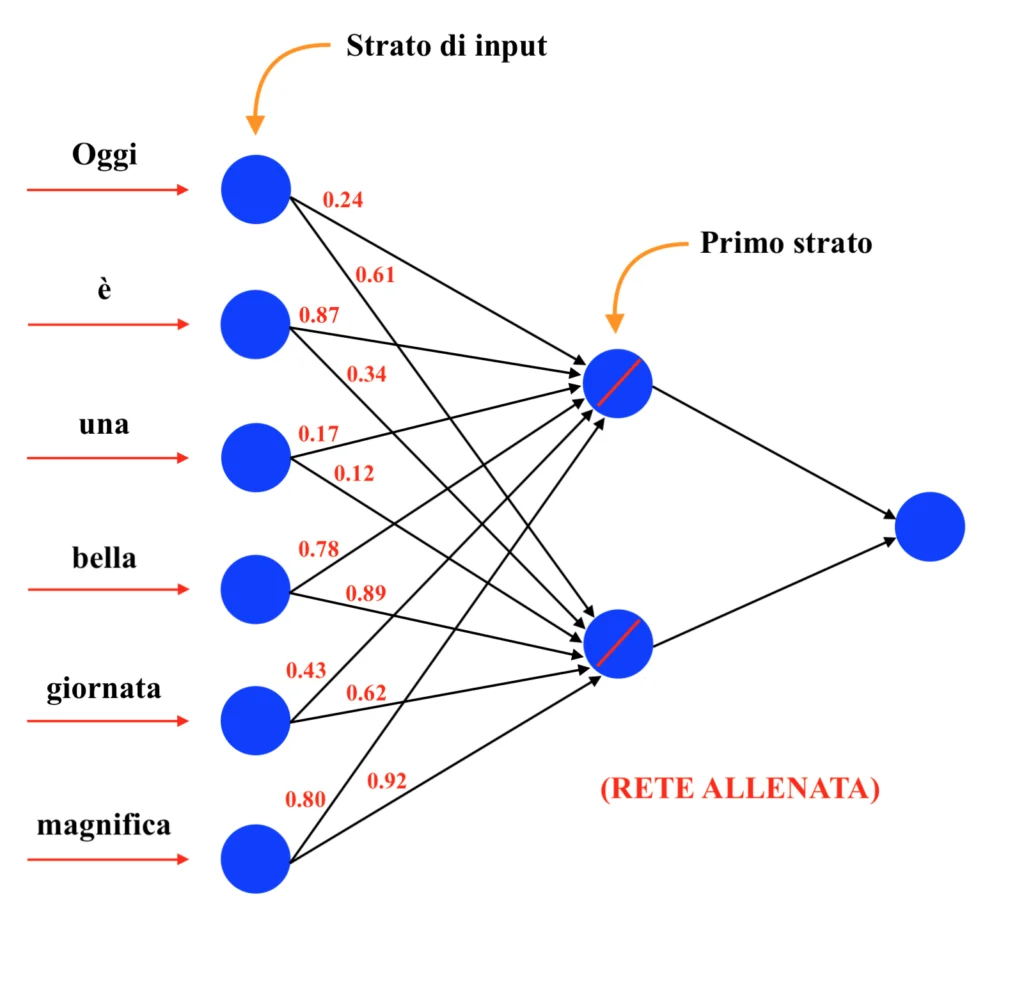
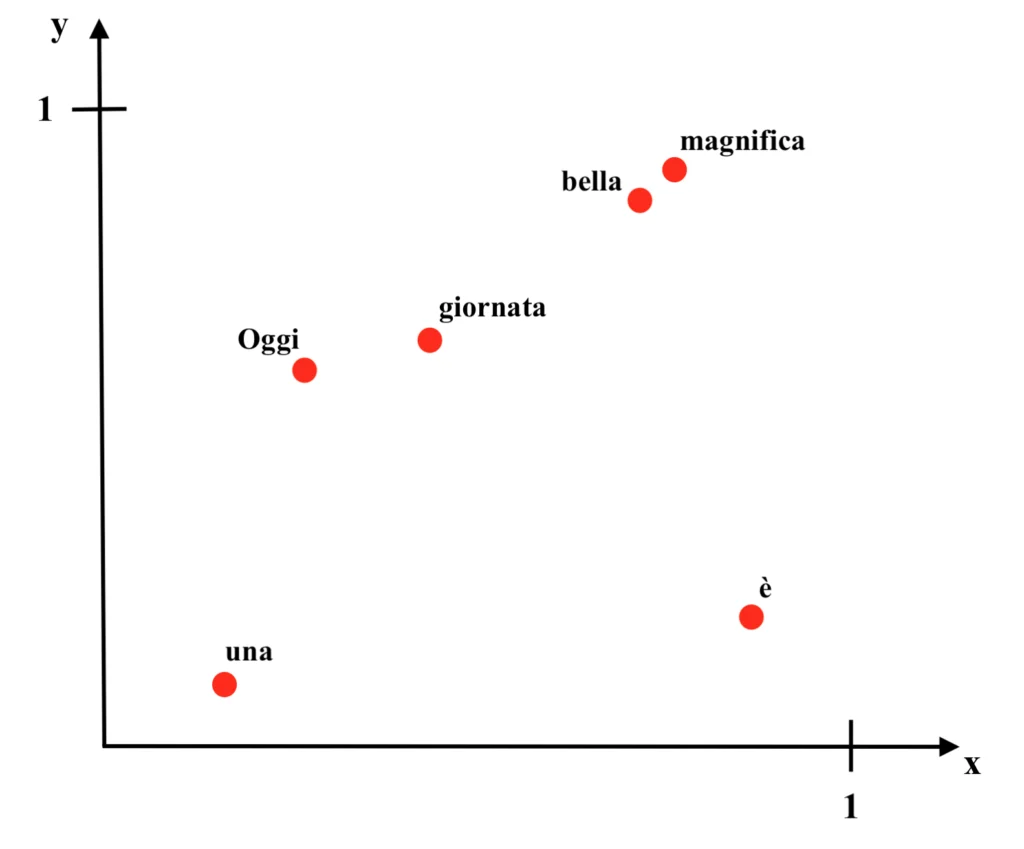
Come si può vedere dalle immagini, una volta allenata la rete neurale sono stati associati vettori simili (ovvero che individuano punti vicini nel grafico) a parole tra loro affini, come appunto “bella” e “magnifica”. I pesi che costituiscono questi nuovi vettori “ottimizzati” sono anche detti “word embeddings” e da qui il nome della procedura di “word embedding”.
Francesco