
Benvenuto nella rubrica How It Works!
Negli ultimi anni i “Large Language Models” (LLM) come ChatGPT, BERT o Claude hanno rivoluzionato il mondo della tecnologia e dell’intelligenza artificiale. Spesso si utilizzano nel quotidiano inconsapevolmente, interagendo con chatbot, motori di ricerca o assistenti virtuali. Ma come funzionano realmente questi modelli? Come riescono a “capire” e generare testo?
Gli LLM sono modelli di Machine Learning (il Machine Learning è uno dei principali campi di studio alla base dell’intelligenza artificiale; se non sai nulla in proposito, leggi il nostro articolo introduttivo sull’argomento!) progettati per generare testi il più possibile fluenti e “naturali”, ovvero simili alla normale produzione scritta umana.
Quando s’interagisce con modelli di questo genere si ha l’impressione che siano in grado di comprendere il testo che viene inserito in input dall’utente (come ad esempio la domanda “Qual è la tua opinione sul riscaldamento globale?”), replicando in modo coerente e puntuale ed argomentando ampiamente le risposte. Sebbene la natura di tale “comprensione” sia tuttora oggetto di accesi dibattiti tra gli esperti del settore (e non), le modalità secondo le quali i modelli LLM elaborano e generano le risposte differiscono in modo sostanziale da quelle umane.
Quando viene posta una domanda ad un essere umano, in un tempo più o meno lungo egli ragiona sull’argomento, compie considerazioni varie sul come rispondere e sul perché rispondere in un determinato modo e solo dopo questo processo restituisce una risposta all’interlocutore.
Il procedimento svolto da un LLM è invece totalmente diverso e per certi versi decisamente difficile da “accettare”, in quanto decisamente contro-intuitivo. Come tutti i modelli di Machine Learning, anche un LLM deve essere “addestrato”, in questo caso su una grande quantità di dati testuali. S’immagini di dover insegnare una lingua straniera ad una persona senza la possibilità di spiegarle direttamente regole grammaticali e sintassi ma solo avendo a disposizione enormi quantità di testi scritti in quella lingua. In linea di massima, più testi quella persona leggerà, più nel tempo comincerà a capire i significati delle parole e le varie regole grammaticali. In modo analogo, durante la fase di addestramento un LLM “legge” grandi quantità di testi adattandosi progressivamente alla lingua ed ai contenuti.
A grandi linee, ciò che rende gli LLM in grado di generare testo è la capacità di elaborare, durante la fase di addestramento, un complesso profilo probabilistico che associ a ciascuna parola la probabilità di comparire, all’interno di una frase, dopo le parole precedenti.
Ad esempio, si consideri la seguente frase:
“Oggi il sole splende ed il cielo è sereno”
Durante la fase di addestramento, il modello vedrà centinaia se non migliaia di frasi simili, “imparando” che, alla frase “Oggi il sole splende ed il cielo è …”, con un alto livello di probabilità seguirà la parola “sereno”. Analizzando miliardi di frasi diverse, il modello associa specifici livelli di probabilità a ciascuna parola in relazione alle diverse frasi che la precedono, rendendosi in grado di generare quindi un testo coerente in risposta all’input scritto.
Scendendo ora maggiormente nello specifico, un concetto centrale per comprendere meglio il funzionamento degli LLM consiste nei cosiddetti “token”. I token sono il “materiale di base” su cui il modello lavora per comprendere e generare il linguaggio e consistono in “rappresentazioni elementari” di parti del testo. Un token può essere una singola parola, un frammento di una parola (un cosiddetto “morfema”), un segno di punteggiatura o un simbolo speciale (come ad esempio l’emoji  ). Più raramente, un token può anche essere un costrutto contenente più parole che generalmente compaiono insieme, come ad esempio “New York”, “Machine Learning” o “Babbo Natale”. La suddivisione del testo in token è una fase essenziale poiché gli LLM non elaborano direttamente intere frasi o parole, bensì una versione “spezzettata” del testo in unità più piccole (in “token”, appunto).
). Più raramente, un token può anche essere un costrutto contenente più parole che generalmente compaiono insieme, come ad esempio “New York”, “Machine Learning” o “Babbo Natale”. La suddivisione del testo in token è una fase essenziale poiché gli LLM non elaborano direttamente intere frasi o parole, bensì una versione “spezzettata” del testo in unità più piccole (in “token”, appunto).
L’assegnazione dei livelli di probabilità non avviene quindi esattamente alle singole parole, bensì ai singoli token. Durante la fase di addestramento di un LLM, il testo viene “tokenizzato”, ovvero suddiviso in “token” ed il modello impara ad associare la probabilità che un certo token o una certa sequenza di token seguano un altro token od un’altra sequenza.
Sebbene intuitivamente sembri impossibile che, procedendo in questo modo, un sistema esclusivamente basato su un tale “stratagemma statistico” sia in grado di produrre testi coerenti ed argomentazioni profonde ed esaustive, è importante considerare che durante la fase di addestramento di questi modelli, come ad esempio il celebre ChatGPT di OpenAI, vengono analizzate quantità oceaniche di dati testuali. Seguono alcuni numeri:
- GPT-3: il primo modello di ChatGPT giunto agli onori della cronaca mondiale è stato addestrato approssimativamente su 300 miliardi di token corrispondenti all’incirca, considerando la “lunghezza media” di un libro, a 2.5 milioni di libri.
- GPT-4: i dettagli sul successore di GPT-3, notoriamente più sofisticato e complesso, non sono stati resi pubblici ufficialmente. Tuttavia, alcune stime parlano di 1000 miliardi di token, corrispondenti all’incirca a 7.5 milioni di libri.
La definizione “Large Language Model” fa riferimento ad una classe di modelli, i quali possono presentare caratteristiche tecniche anche molto diverse tra loro. In generale, tuttavia, il cuore degli LLM più sofisticati è costituito da una particolare architettura di rete neurale (non sai nulla sulle reti neurali? Leggi il nostro articolo sull’argomento!) di recente invenzione, nota come “Transformer”. Nel seguito saranno analizzate a grandi linee le caratteristiche principali dell’architettura “Transformer”, con particolare riferimento alle modalità di addestramento di tale particolare rete neurale. Nella seguente immagine è riportato uno schema dell’architettura:
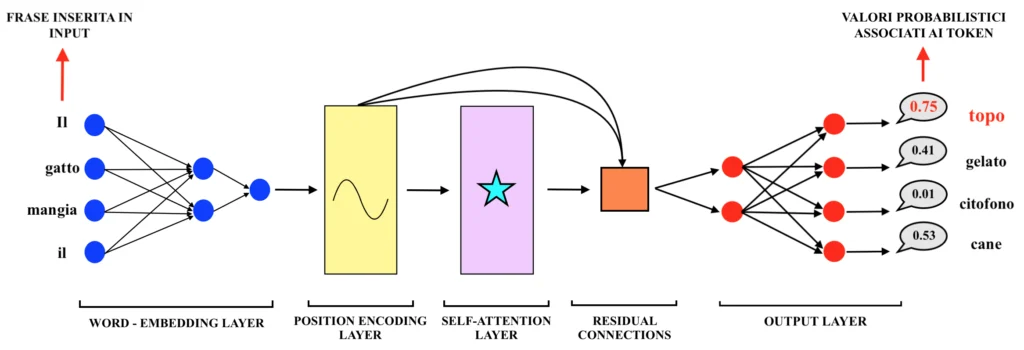
Di seguito si descriveranno quindi la struttura e gli step principali del procedimento di addestramento e previsione di un modello LLM:
Tokenizzazione del testo: prima di tutto, il modello LLM deve “leggere” il testo in un formato che può “comprendere”. Trattandosi di un modello matematico, il testo inserito in input durante la fase di addestramento deve necessariamente essere tradotto in un’informazione numerica. Se la frase di input è “Il sole splende”, il modello potrebbe lavorare su tre token distinti (“il”, “sole” e “splende”). Ogni token viene tradotto in una rappresentazione numerica attraverso un processo chiamato “word embedding”. Tale rappresentazione numerica consiste in un vettore di numeri in grado di garantire quanto segue:
- Univocità del token: ciascun vettore identificherà un token in modo univoco, ovvero a ciascun token corrisponderà un vettore diverso da tutti gli altri.
- Similarità tra token: token simili avranno vettori “simili” tra loro numericamente. Ma cosa significa simili? Considerando il vettore come un punto in uno spazio n– dimensionale, avente tante dimensioni quanti sono i valori che compongono il vettore (ad esempio, se il vettore ha 3 dimensioni, il token sarà un punto in uno spazio tridimensionale), due token “simili” (come ad esempio potrebbero essere le parole “torta” e “crostata”) saranno due punti vicini all’interno dello spazio. Come si può intuire, la creazione di token “numericamente simili” facilita il modello nel prevedere i token sulla base del contesto (ovvero sulla base dei token precedenti all’interno di una frase).
I valori contenuti in tali “vettori di embedding” non sono altro che i pesi di una rete neurale, la quale costituisce il primo strato dell’architettura “Transformer” (come si può vedere dalla precedente immagine), addestrata a mappare le correlazioni tra i vari token sulla base dei testi inseriti in input. La procedura di “word embedding”, cruciale per il funzionamento dei modelli LLM, verrà approfondita nel dettaglio in un prossimo articolo, perciò resta sintonizzato!
Elaborazione del testo tokenizzato: i vettori associati a ciascun token del testo inserito in input passano quindi attraverso i seguenti blocchi funzionali del modello LLM. Dunque:
- Strato di “position encoding”: la fase di “position encoding” serve a fare sì che il modello sia in grado di considerare l’ordine dei token in una frase. Tale funzionalità è necessaria poiché, a differenza di altri tipi di reti neurali, come ad esempio le reti neurali ricorrenti, i “Transformer” non elaborano i dati in sequenza, bensì “vedono tutti i token contemporaneamente” (esattamente come avviene nelle reti neurali tradizionali, in gergo tecnico chiamate “Multi – Layer Perceptron”). In sostanza, la fase di “position encoding” genera un’informazione numerica coerente con la posizione del token nella frase e la somma al vettore realizzato nella precedente fase di “word embedding”. Si considerino ad esempio le seguenti due frasi:
“Il gatto mangia il topo” – “Il topo mangia il gatto”
Il “position encoding” permette al modello di distinguere la differenza tra le due frasi, segnalando che il token “gatto” viene primo di “topo” nella prima e viceversa nella seconda. All’interno dello strato di “position encoding”, diversamente dallo strato primo strato di “word embedding”, non sono presenti pesi soggetti a calibrazione durante la procedura di addestramento del modello LLM; questo significa che le modalità che permettono al modello LLM di distinguere due frasi simili sulla base della posizione delle parole sono fisse (o, per meglio dire, “deterministiche”) e non vengono affinate durante la fase di addestramento.
- Strato di “self-attention”: il meccanismo di “self-attention” è uno degli elementi centrali dell’architettura “Transformer”, nonché una delle più recenti e rivoluzionarie innovazioni nell’intero campo del Machine Learning (illustrata nel celebre articolo “Attention is All You Need”, pubblicato nel 2017 da un gruppo di ricercatori di Google [1]) ed è ciò che permette al modello LLM di capire quali token in una frase sono più rilevanti in base al contesto. Tramite tale meccanismo viene calcolata l’importanza di ogni token rispetto agli altri all’interno della stessa frase, permettendo al modello di focalizzarsi su parole specifiche particolarmente rilevanti per il significato complessivo della frase. Ad esempio, si consideri la seguente frase:
“Il gatto mangia il pesce perché ha fame”
Da un punto di vista sintattico, la parola “ha” potrebbe riferirsi sia alla parola “gatto” sia alla parola “pesce”; il meccanismo di “self-attention” permette al modello LLM di “capire” che “ha fame” si riferisce al gatto e non al pesce in quanto il modello impara a dare maggiore peso al token “gatto” piuttosto che al token “pesce” in quello specifico contesto. Diversamente dalla fase di “position encoding” in questo caso durante l’addestramento del modello sono calibrati dei pesi numerici che rappresentano quanto ciascun token deve “dare attenzione” agli altri token nella sequenza. Un valore più alto del peso significa che il token deve prestare molta attenzione a un altro specifico token. Per esempio, nella frase sopra, il token “gatto” potrebbe dare un peso alto al token “mangia” (ad esempio, un peso pari a 0.8) perché il gatto è colui che compie l’azione di mangiare, un peso medio a “pesce” (ad esempio, un peso pari a 0.5) perché è l’oggetto dell’azione e un peso basso a “il” (ad esempio, un peso pari a 0.1) in quanto l’articolo non aggiunge molto al significato del verbo o del soggetto.
- Connessioni residuali: le connessioni residuali poste dopo lo strato di “self- attention” svolgono un ruolo cruciale nel migliorare l’efficacia dell’addestramento e le performance del modello. Tali connessioni danno la possibilità al modello di sommare l’input dello strato di “self-attention” (ovvero l’output della fase di “position encoding”) all’output dello strato stesso, permettendo di fatto all’architettura “Transformer” di conservare l’informazione originale che spesso rischia di andare perduta durante le trasformazioni avvenute all’interno del layer.
Previsione: l’output risultante dalle connessioni residuali viene quindi inserito all’interno di una classica architettura feed-forward (una classica rete neurale “completamente connessa” come un “multi – layer perceptron”) la quale restituisce in output il profilo probabilistico relativo all’intero vocabolario gestito dal modello LLM; sulla base di tale profilo probabilistico, il modello LLM produce dunque la previsione sul token successivo della sequenza. Ogni volta che produce una parola in output, il modello considera dunque l’intera distribuzione di probabilità associata all’intero vocabolario di token analizzato durante la fase di addestramento e seleziona il token con la probabilità più alta (in realtà, non sempre seleziona quello con la probabilità più alta, ma questa caratteristica dei modelli LLM, anche detta “temperatura del modello”, verrà analizzata in un prossimo articolo dedicato!).
Calcolo dell’errore di previsione e calibrazione dei pesi: come in qualsiasi altro modello di Machine Learning, l’obiettivo finale dell’addestramento è la calibrazione dei pesi interni al modello. Tale calibrazione avviene, come illustrato in questo articolo, tramite l’algoritmo di addestramento delle reti neurali noto come “algoritmo di backpropagation”. Una buona calibrazione dei pesi farà sì che, una volta addestrato il modello, l’output restituito dal modello allenato sia coerente con l’input inserito dall’utente. La calibrazione dei pesi avviene confrontando la previsione effettuata con l’output corretto (il quale, durante la fase di addestramento, è noto). Ad esempio:
DURANTE LA FASE DI TRAINING: Input tokenizzato: “Il sole splende nel” Risultato corretto: “cielo”
Risultato previsto dal modello: “forno”
La distanza numerica tra la parola “cielo” e la parola “forno” costituisce l’entità dell’errore sulla base della quale i pesi vengono calibrati. Una volta ricalibrati i pesi, il modello LLM sarà più incline a restituire la parola “cielo” dopo la frase “il sole splende nel” rispetto a quanto lo fosse in precedenza.
Durante l’algoritmo di backpropagation, il processo di ricalibrazione dei pesi viene ripetuto per molte iterazioni fino a quando il modello non raggiunge una performance predittiva soddisfacente (quantificata in base all’entità dell’errore complessivo).
Francesco