
Benvenuto nella rubrica How It Works!
Le “macchine a vettori di supporto” (in inglese Support Vector Machines – SVM) costituiscono una potente tecnica di Machine Learning supervisionato utilizzata prevalentemente per affrontare problemi di classificazione. Segue un esempio.
Si ipotizzi di voler prevedere se un particolare dosaggio di un farmaco sia o meno efficace per curare una malattia. Si dispone quindi di un dataset i quali dati sono descritti solamente da due variabili: il dosaggio e l’efficacia nella cura della malattia (quest’ultima è la variabile oggetto di classificazione, anche detta “etichetta”). Di seguito è riportata una rappresentazione grafica dei dati. Dunque:

Come si può facilmente intuire dall’immagine, alti dosaggi del farmaco si dimostrano efficaci per curare la malattia, mentre a bassi dosaggi il farmaco risulta inaffidabile. In questo caso un semplice modello previsionale può essere ricavato tracciando una linea di separazione equidistante dai due “elementi di frontiera” del dataset, come riportato di seguito. Dunque:
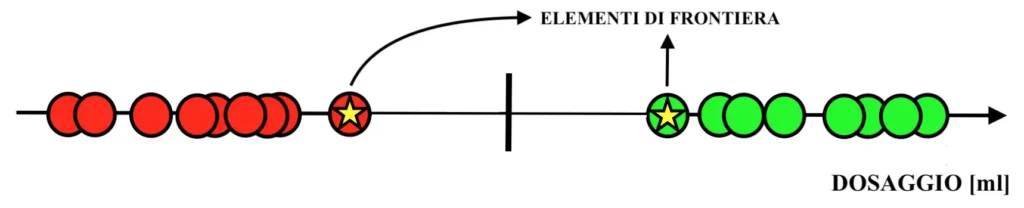
In questo modo, volendo prevedere l’efficacia di un nuovo dosaggio del farmaco del quale non si conosce l’affidabilità, sarebbe semplicemente necessario controllare se si collochi a sinistra o a destra della linea di separazione. Se si colloca a sinistra, il nuovo dosaggio non si prevede sia efficace, se si colloca a destra si prevede che potrà curare con successo la malattia. Dunque:
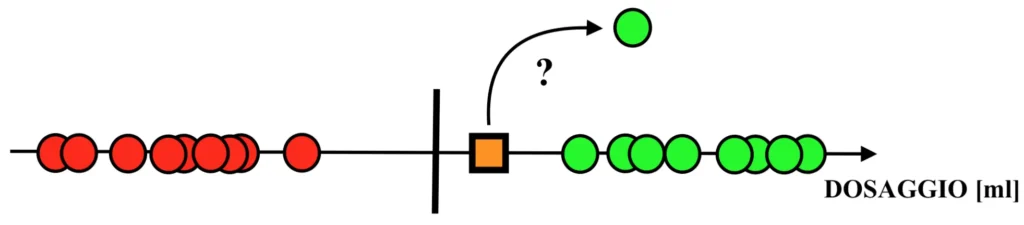
Tuttavia, cosa succede se, come nella seguente immagine, i dati del dataset non sono separabili tramite un unico valore centrale?

Come si può facilmente intuire, in questo caso non esiste una linea di demarcazione in grado di separare i dati in dosaggi efficaci e non efficaci.
In quest’ultimo caso, al fine di separare i dati sono necessarie nuove informazioni su di essi, ovvero nuove variabili.
Si ipotizzi quindi che l’età del paziente influenzi l’efficacia del farmaco. Aggiungendo dunque al dataset una variabile denominata “età del paziente”, i dati saranno rappresentabili come segue. Dunque:
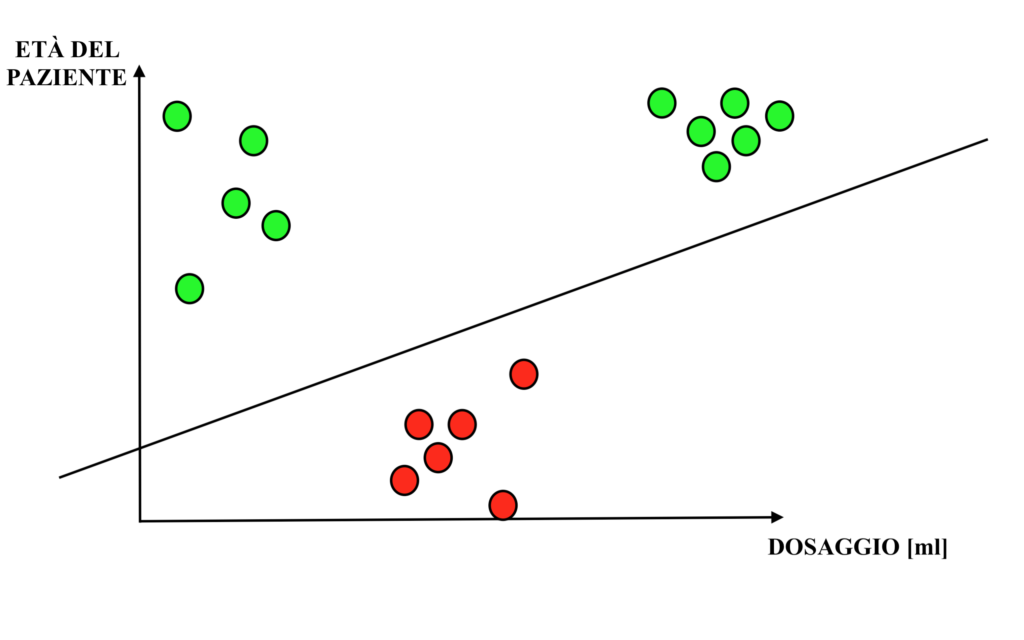
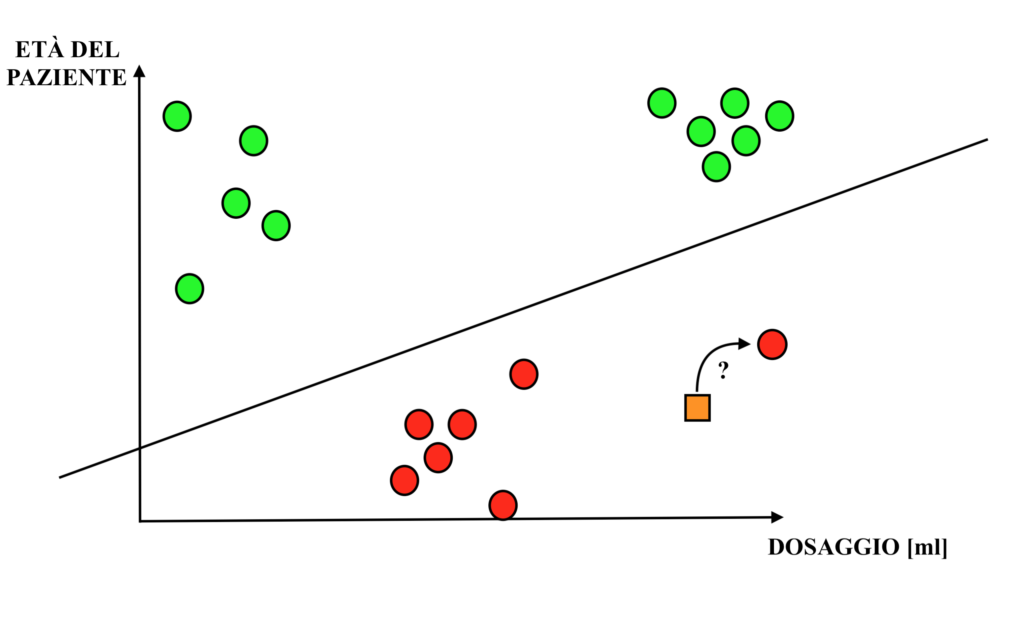
Come si può osservare dal grafico, aggiungendo l’informazione sull’età del paziente risulta nuovamente possibile tracciare una linea di separazione tra le somministrazioni del farmaco efficienti per la cura della malattia e quelle non efficienti.
Una nuova osservazione, ovvero una nuova dose del farmaco somministrata ad un paziente di una determinata età, sarà quindi prevedibile come efficace o non efficace. Dunque:
Fino ad ora, tuttavia, non si è ancora parlato di Support Vector Machines.
Le Support Vector Machines (SVM) si dimostrano molto utili nei casi in cui i dati non sono classificabili in modo corretto tramite una sola variabile (come ad esempio il dosaggio) e non si dispone di altre informazioni (come ad esempio l’età del paziente).
Per ovviare a questo problema le SVM sfruttano un ingegnoso stratagemma matematico in grado di costruire artificialmente nuove variabili.
Tornando all’esempio dei dosaggi, non disponendo della variabile “età del paziente”, nel caso in cui i dati non fossero linearmente separabili, come visto precedentemente, ci si troverebbe nella condizione di non poter effettuare alcuna previsione utile.
Sfruttando una SVM tuttavia, i dati del dataset contenente come unica variabile il dosaggio saranno “trasportati” in uno spazio a dimensionalità maggiore attraverso un particolare “trucco”, in gergo definito “kernel trick”. Ad esempio, impostando un cosiddetto “kernel polinomiale”, una nuova variabile può essere definita come il quadrato (o il cubo) dei dosaggi, portando i dati monodimensionali (ovvero aventi solamente la variabile indipendente il “dosaggio”) nel seguente diagramma bidimensionale. Dunque:
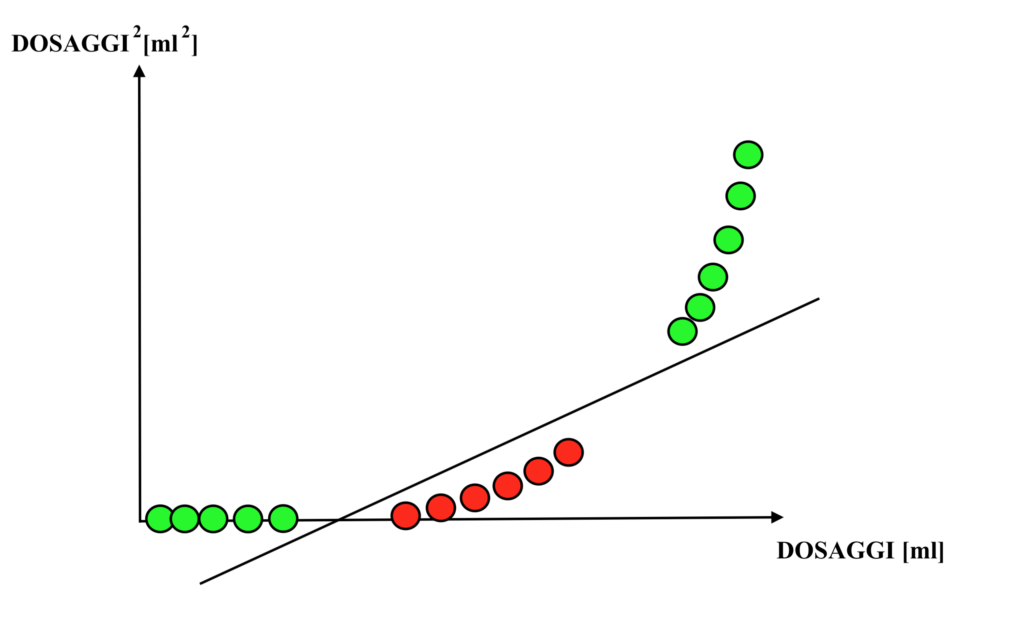
Come si può osservare dal grafico, dopo la trasformazione i dati sono nuovamente separabili tramite una retta, in modo del tutto simile a come lo erano una volta introdotta la variabile “età del paziente”; risulta quindi possibile classificare in modo esatto i nuovi dosaggi come “efficaci” o “non efficaci”.
Anche non disponendo di nuove informazioni infatti (ovvero di nuove variabili reali, come l’età del paziente), è probabile che un dosaggio molto vicino ad un altro sia ugualmente efficace!
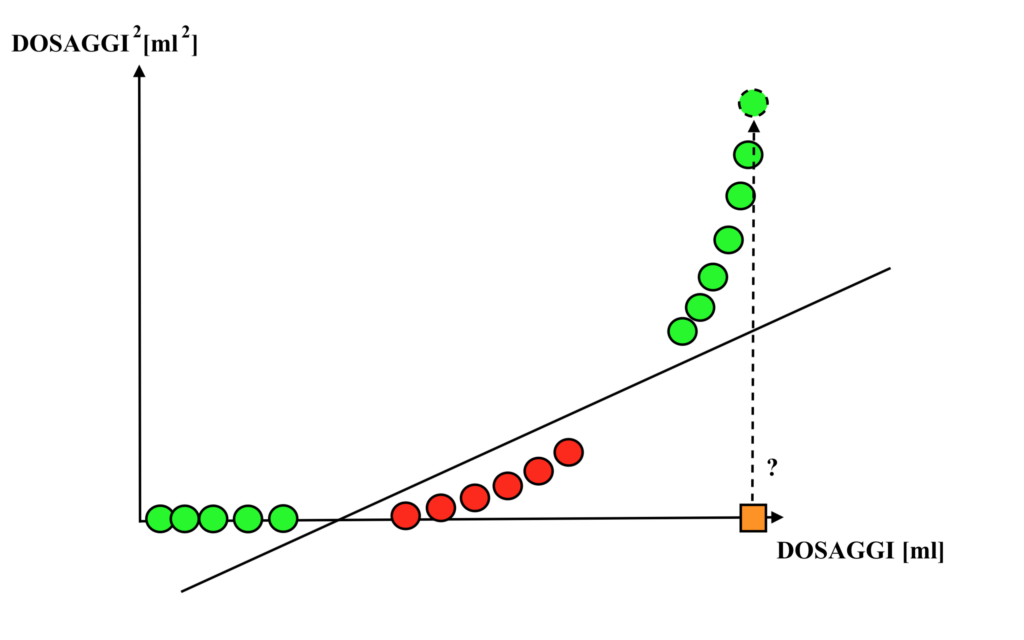
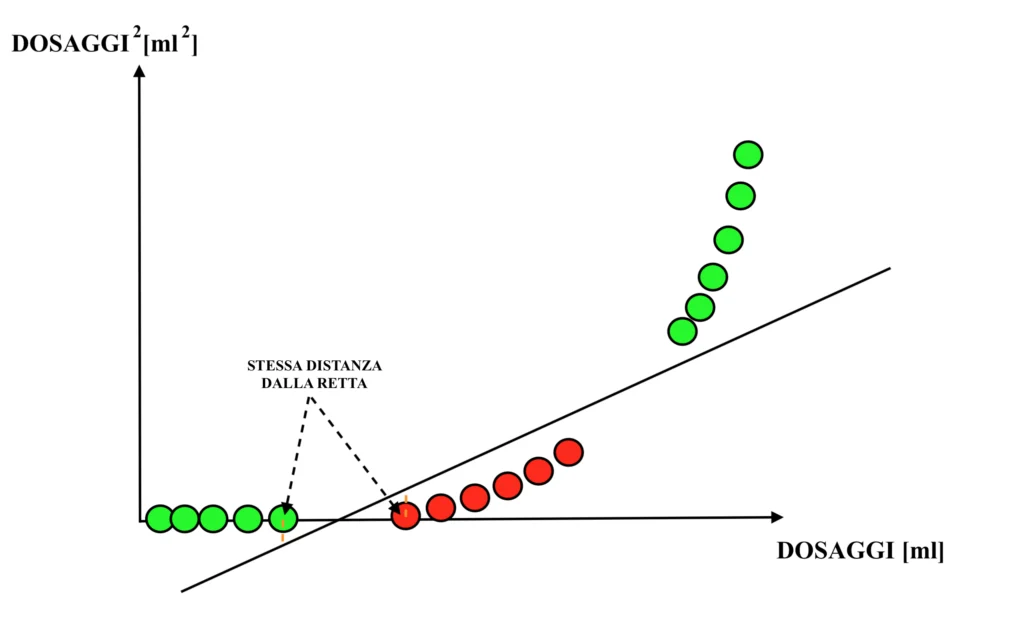
Nello specifico, le Support Vector Machines, una volta definita la modalità di trasformazione dello spazio delle variabili originale (nel caso del kernel polinomiale, una volta definito il grado del polinomio), durante il training cercano la retta (più precisamente, l’“iperpiano”) in grado di separare le osservazioni in modo da massimizzare la distanza tra le “osservazioni di frontiera”, ovvero tra le osservazioni di una categoria più vicine a quelle dell’altra.
Ti è mai capitato di utilizzare le Support Vector Machine in un progetto applicativo? Sentiti libero di raccontarci la tua esperienza nei commenti!
Francesco