
Benvenuto nella rubrica How It Works!
In questo articolo introdurremo un primo semplice algoritmo di Reinforcement Learning, quasi mai utilizzato nella pratica ma importante per famigliarizzare con le modalità secondo le quali un agente agisce all’interno di un ambiente virtuale.
L’algoritmo in questione prende il nome di “epsilon – greedy” (tipicamente citato semplicemente come “ε-greedy”) e appartiene, al di fuori dell’ambito del Machine Learning, alla grande famiglia degli algoritmi di ottimizzazione “greedy” (in inglese, “goloso”), i quali implementano soluzioni tipicamente semplici e basate sul concetto di “ricerca della ricompensa immediata”.
Prima di tutto, è di fondamentale importanza introdurre i concetti di “esplorazione” (in inglese, “exploration”) e “sfruttamento” (in inglese, “exploitation”) in ambito di Reinforcement Learning. Dunque:
- Esplorazione: comportamento secondo il quale un agente mira ad acquisire nuova conoscenza circa l’ambiente nel quale si muove, in modo da ricercare modalità secondo le quali raggiungere performance ancora maggiori rispetto a quelle raggiungibili semplicemente basandosi sulla sua conoscenza corrente.
- Sfruttamento: comportamento secondo il quale un agente mira a massimizzare la sua performance (ricordiamo, definita come “massima ricompensa cumulata”) basandosi, ad ogni step, esclusivamente sulla sua corrente conoscenza dell’ambiente nel quale si muove.
Nell’ambito di una procedura di training ed anche una volta allenato e pronto all’uso, muovendosi nell’ambiente virtuale un agente si trova dunque davanti alla necessità di trovare la migliore soluzione circa un compromesso a tutti noi molto famigliare: “continuo a perseguire i miei obiettivi contando sulle conoscenze che già possiedo, oppure accetto il rischio di esplorare nuove strategie al fine di accumulare nuova conoscenza potenzialmente preziosa?”.
A tal proposito, segue una frase tratta da una lezione tenuta alla University College London (UCL) da Hado Van Hasselt, ricercatore di DeepMind:
“Sometimes you have to make a short walk throug the rain to find a brilliant new place to go to”
“Spesso serve una breve passeggiata sotto la pioggia per scoprire un nuovo posto meraviglioso”
Difficile trovarsi in disaccordo.
In linea di massima dunque, se una strategia sconosciuta o con la quale si ha poca famigliarità non viene mai sperimentata, difficilmente si potranno trarre conclusioni in merito alla sua efficacia.
Nella pratica del Reinforcement Learning dunque ci si trova spesso ad affrontare il seguente dilemma: “utilizzo un modello maggiormente portato per l’esplorazione o più incline allo sfruttamento della conoscenza pregressa?”. Ovviamente non esiste una regola aurea e la risposta sarà sempre la stessa: dipende.
Prima di introdurre l’algoritmo “ε-greedy” diamo un breve sguardo ad una sua semplificazione (la qual, come si vedrà in seguito, difficilmente può avere una qualche applicazione pratica), ovvero il puro algoritmo “greedy”.
Algoritmo “greedy”: nel precedente articolo intitolato “Il Reinforcement Learning” abbiamo introdotto il concetto di “action – value function”, funzione attraverso la quale un agente stima la ricompensa attesa effettuando una specifica azione a partire da un determinato stato.Un agente che implementa l’algoritmo greedy sceglie ad ogni step se eseguire una determinata azione utilizzando la action – value function per stimarne la bontà rispetto alle altre. Nel caso dell’algoritmo greedy, tale stima consiste semplicemente nel calcolo della media aritmetica delle ricompense ottenute in passato ogniqualvolta è stata scelta quella specifica azione in quel determinato stato. Ipotizzando per semplicità un ambiente nel quale è presente solamente un possibile stato e la performance dell’agente si riduce solamente a scegliere l’azione migliore in quello stato (rendendo quindi l’action – value function indipendente dallo stato), l’algoritmo greedy si articolerà nei seguenti due semplici passaggi iterativi. Dunque:
PASSAGGIO 1: stimare la ricompensa attesa di tutte le possibili azioni.
PASSAGGIO 2: scegliere l’azione alla quale corrisponde la stima di valore più alto; se tutte le stime hanno lo stesso valore, scegliere in modo casuale una tra le azioni possibili.
Nella seguente immagine è riportato un semplice esempio pratico di algoritmo greedy, nel quale un agente che si trova in un ambiente a stato singolo può scegliere se eseguire l’azione A, B o C, aspettandosi in risposta una ricompensa pari a 0 o ad 1. Dunque:
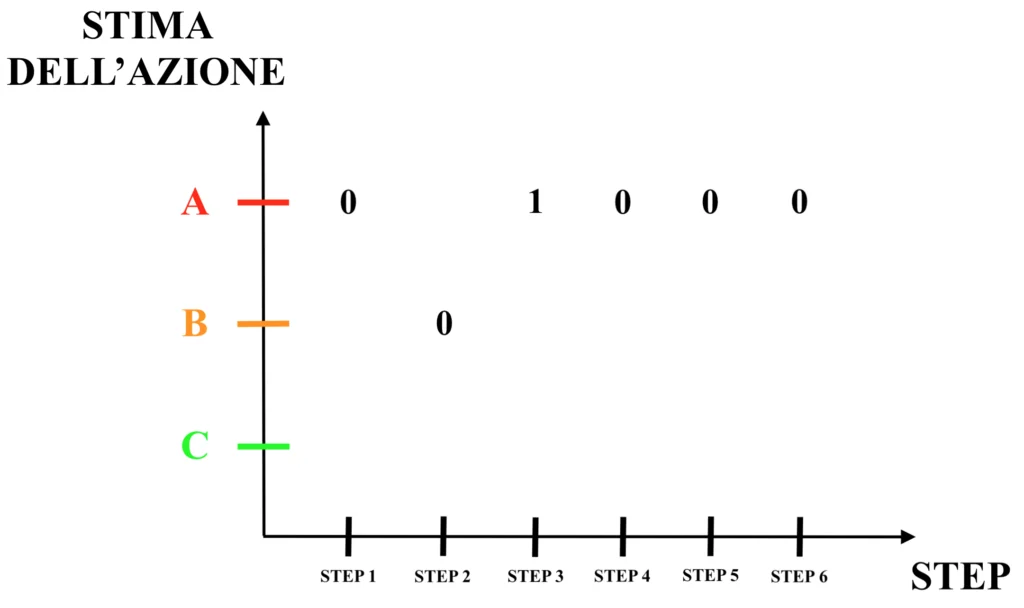
L’agente comincia al primo step scegliendo, ovviamente in modo casuale (in quanto scelta iniziale), l’azione A ed ottenendo una ricompensa pari a 0.
In corrispondenza dello step 2 la scelta è ancora casuale, in quanto la media aritmetica delle ricompense passate di ciascuna delle tre azioni è pari a 0; l’agente sceglie l’azione B ed ottiene anche in questo caso una ricompensa pari a 0.
Scegliendo, ancora una volta casualmente, l’azione A in corrispondenza dello step 3, l’agente ottiene la sua prima ricompensa pari ad 1.
Come si può vedere dall’immagine, una volta ottenuta la ricompensa pari ad 1 in risposta alla scelta dell’azione A, la scelta dell’agente in ciascuno degli step successivi sarà sempre l’azione A, in quanto la media delle ricompense passate sarà per sempre più alta rispetto a quella delle azioni B e C, le quali sono così definitivamente abbandonate.L’algoritmo greedy sceglie quindi in maniera “vorace” (o “golosa”, appunto) l’azione per la quale ha avuto almeno una volta l’evidenza della possibilità di ottenere una ricompensa positiva. Tralasciando le ovvie considerazioni sull’inutilità pratica di questo modello, si osserva quindi come l’algoritmo greedy sia “ciecamente” orientato allo sfruttamento della conoscenza pregressa, non contemplando minimamente, non appena un’azione si dimostra efficace, la possibilità di esplorare altre strategie. Nell’esempio, l’azione B rimarrà per l’eternità effettuata solamente in un caso, mentre l’azione C nemmeno una volta. Per quanto “ne sa” l’agente, l’azione C avrebbe potenzialmente potuto restituire una ricompensa pari ad 1 in ogni singolo step; nonostante questo, non sarà mai scelta.
Algoritmo “ε-greedy”: l’algoritmo ε-greedy risolve il problema dell’assoluta mancanza di esplorazione dell’algoritmo greedy introducendo un fattore di casualità (il parametro ε, appunto) che permette all’agente di scegliere, talvolta, azioni che non presentano il più alto valore di stima. In particolare, l’agente sceglierà in corrispondenza di ogni step l’azione con il più alto valore di stima (esattamente, come nel caso dell’algoritmo greedy, calcolando la media della ricompense passate), tuttavia secondo un valore di probabilità pari ad 1 – ε. Se nell’algoritmo greedy l’azione con il massimo valore di stima veniva sempre scelta in modo certo, ovvero con probabilità pari ad 1, in questo caso tale scelta non sarà più obbligata, in quanto avverrà con una probabilità inferiore ad 1. L’agente sarà quindi tanto più portato ad esplorare le azioni apparentemente meno valide tanto più verrà impostato inizialmente un alto valore del parametro ε. Nella seguente immagine si applica quindi l’algoritmo ε-greedy all’esempio precedente. Dunque:

Mediante l’algoritmo ε-greedy si mantiene quindi una certa ragionevole probabilità (generalmente bassa) di saggiare le potenzialità di azioni apparentemente non così valide, optando quindi per un compromesso tra la tendenza all’esplorazione e la tendenza allo sfruttamento della conoscenza pregressa.
Nei prossimi articoli sul tema del Reinforcement Learning analizzeremo modelli ed algoritmi più complessi ed sfruttati nella pratica, quindi resta sintonizzato!
Francesco